Operator:固化到软件中的运维技能
原文:Introducing Operators: Putting Operational Knowledge into Software
SRE 是用开发软件的方式来进行应用运维的人。他们是工程师、开发者,通晓如何进行软件开发,尤其是特定应用域的开发。他们做出的东西,就是包含这一应用的运维领域技能的软件。
我们的团队正在 Kubernetes 社区进行一个概念的设计和实现,这一概念就是:在 Kubernetes 基础之上,可靠的创建、配置和管理复杂应用的方法。
我们把这种软件称为 Operator。一个 Operator 指的是一个面向特定应用的控制器,这一控制器对 Kubernetes API 进行了扩展,使用 Kubernetes 用户的行为方式,创建、配置和管理复杂的有状态应用的实例。他构建在基础的 Kubernetes 资源和控制器概念的基础上,但是包含了具体应用领域的运维知识,实现了日常任务的自动化。
无状态容易,有状态难
在 Kubernetes 的支持下,管理和伸缩 Web 应用、移动应用后端以及 API 服务都变得比较简单了。其原因是这些应用一般都是无状态的,所以 Deployment 这样的基础 Kubernetes API 对象就可以在无需附加操作的情况下,对应用进行伸缩和故障恢复了。
而对于数据库、缓存或者监控系统等有状态应用的管理,就是个挑战了。这些系统需要应用领域的知识,来正确的进行伸缩和升级,当数据丢失或不可用的时候,要进行有效的重新配置。我们希望这些应用相关的运维技能可以编码到软件之中,从而借助 Kubernetes 的能力,正确的运行和管理复杂应用。
Operator 这种软件,使用 TPR(第三方资源,现在已经升级为 CRD) 机制对 Kubernetes API 进行扩展,将特定应用的知识融入其中,让用户可以创建、配置和管理应用。和 Kubernetes 的内置资源一样,Operator 操作的不是一个单实例应用,而是集群范围内的多实例。

为了展示 Operator 的概念,我们有两个实际的例子开放了源代码:
- etcd Operator,创建、配置和管理 etcd 集群。etcd 是一个可靠的分布式键值库,由 CoreOS 出品,用于分布式系统中的关键数据存储,Kubernetes 就是用户之一。
- Prometheus Operator,创建配置和管理 Prometheus 监控实例。Prometheus 是一个强大的监控、指标和告警工具,也是 CoreOS 团队支持的 CNCF 项目。
Operator 如何构建?
Operator 基于两个 Kubernetes 的核心概念:资源和控制器。例如内置的 ReplicaSet 资源让用户能够设置指定数量的 Pod 来运行,Kubernetes 内置的控制器会通过创建或移除 Pod 的方式,来确保 ReplicaSet 资源的状态合乎期望。Kubernetes 中有很多基础的控制器和资源用这种方式进行工作,包括 Service,Deployment 以及 DaemonSet。
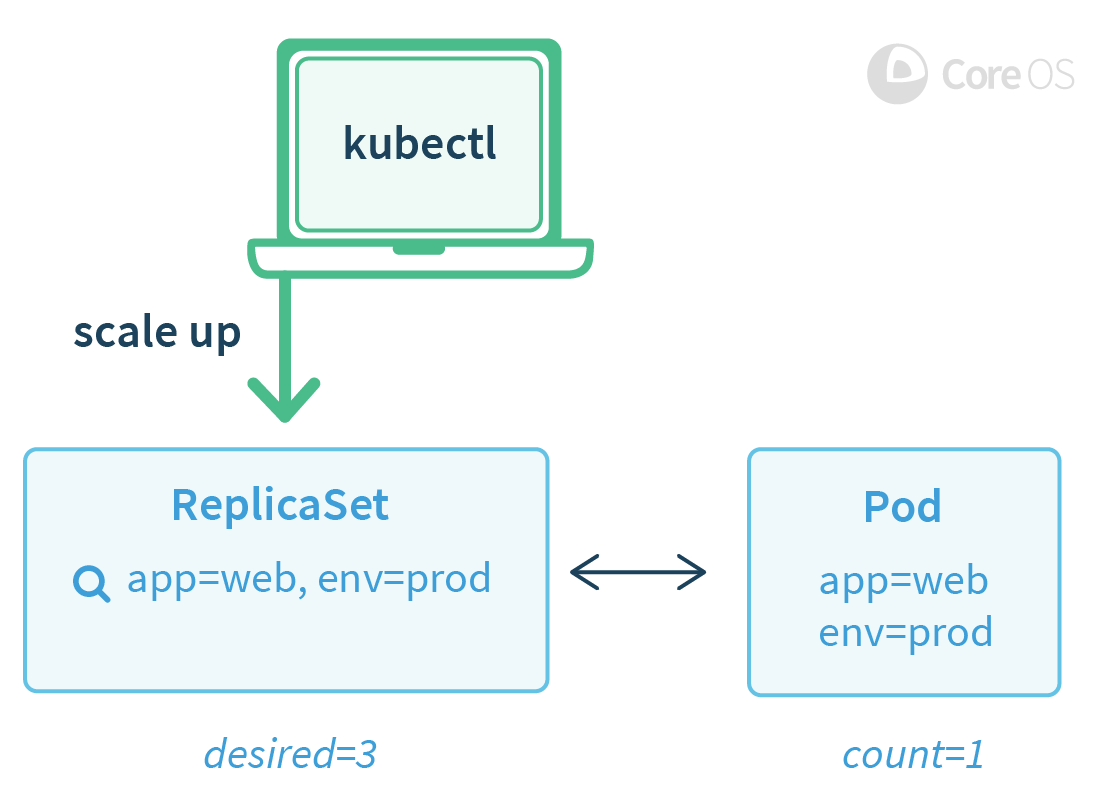
用户将一个 Pod 的 RS 扩展到 三个
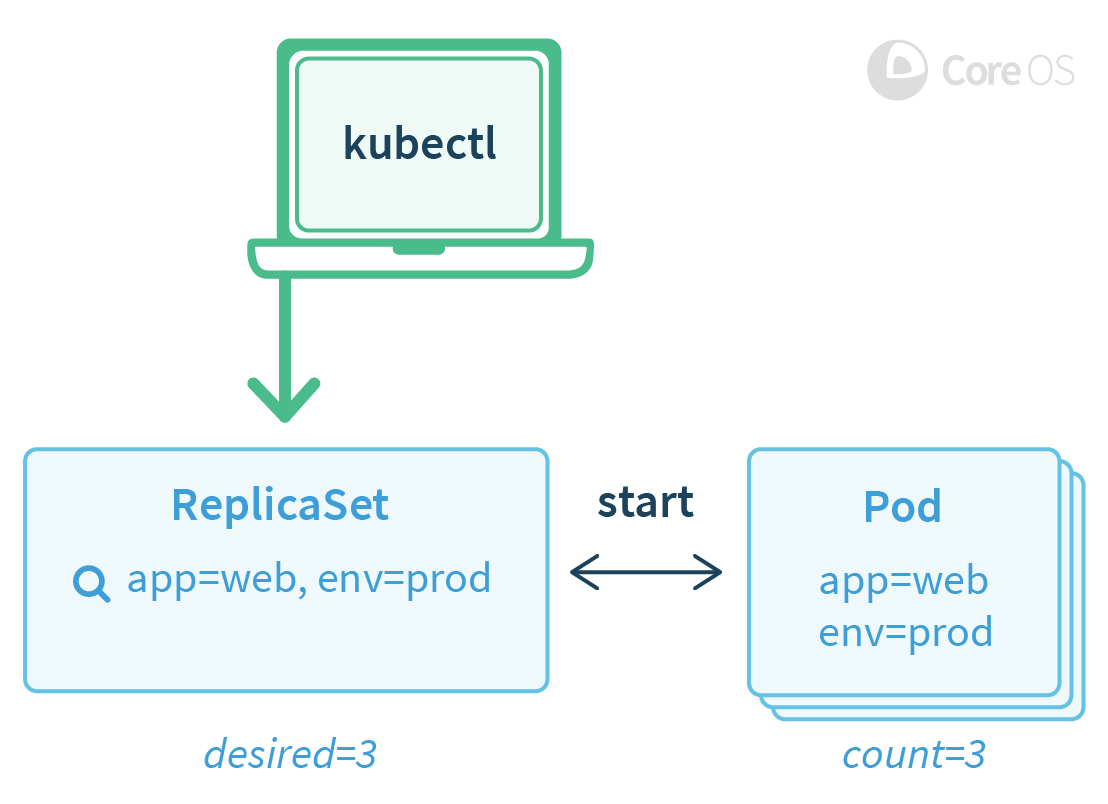
一段时间之后,Kubernetes 的控制器按照用户意愿创建新的 Pod。
Operator 在基础的 Kubernetes 资源和控制器之上,加入了相关的知识和配置,让 Operator 能够执行特定软件的常用任务。例如当手动对 etcd 集群进行伸缩的时候,用户必须执行几个步骤:为新的 etcd 示例创建 DNS 名称,加载新的 etcd 示例,使用 etcd 管理工具(etcdctl member add)来告知现有集群加入新成员。etcd Operator 的用户就只需要简单的把 etcd 的集群规模字段加一而已。
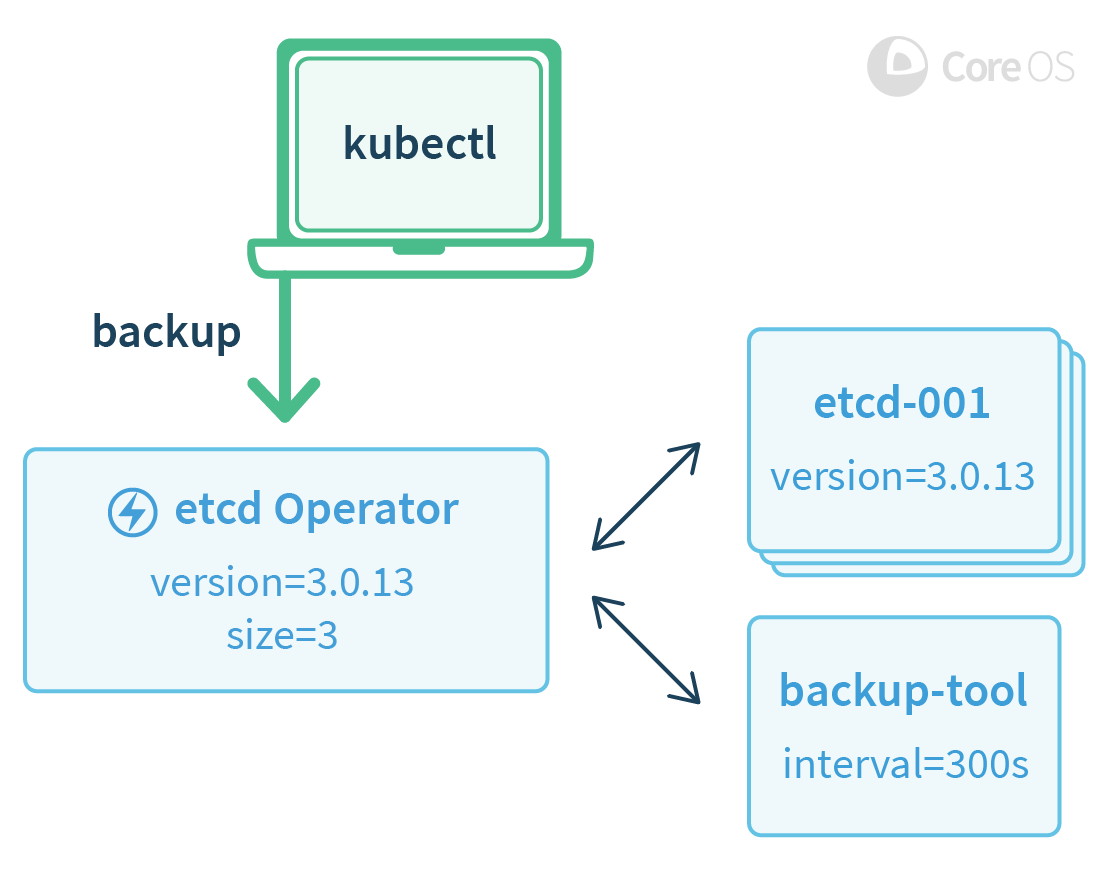 > 用户使用 kubectl 触发了一次备份
> 用户使用 kubectl 触发了一次备份
复杂的管理任务还有很多,包括应用升级、配置备份、原生 Kubernetes API 的服务发现,应用的 TLS 认证配置以及灾难恢复等。
如何创建一个 Operator
根据前面的陈述,我们知道 Operator 是跟应用紧密相关的,所以其中最重要的工作就是把应用自身的运维方法编码成为资源和控制逻辑。在创建 Operator 的过程中,我们发现了一些适用于各种应用的通用模式:
- Operator 应该以单一 Deployment 的形式进行安装。
kubectl create -f https://coreos.com/operators/etcd/latest/deployment.yaml,不应进行其他额外操作。 - Operator 在安装到 Kubernetes 中时,应该创建新的 TPR 类型。用户会使用这一类型来创建新的应用实例。
- Operator 应该尽量利用 Kubernetes 内置的 Service 以及 ReplicaSet 这些经过良好的测试并易于理解的原生对象。
- Operator 应该向后兼容,并且保持对过去版本资源的理解能力。
- 在 Operator 出现故障或者被移除的时候,相关应用应该持续运行不受影响。
- 用户应该从 Operator 中获得声明特定版本以及编排应用版本升级的能力。无法更新的软件应该是一种运维缺陷,也可能造成安全问题,Operator 应该给用户更多信心和辅助,完成升级操作。
- Operator 应该用“Chaos Monkey”这样的测试套件来模拟 Pod、配置或者网络故障的情况下的运行情况。
Operators 的未来
CoreOS 所发布的 etcd 和 Prometheus 的 Operator,展示了 Kubernetes 平台的能力。过去一年中,我们和 Kubernetes 社区紧密合作,聚焦于 Kubernetes 的稳定性、安全性、以及管理和安装的方便性方面的工作。
现在 Kubernetes 的基础已经奠定,我们新的工作重点转移到了上层建筑:用软件来对 Kubernetes 进行扩展,为其赋予新的能力。我们想象,未来用户在各自的 Kubernetes 集群上安装 Postgress Operator、Cassandra Operator 或者 Redis Operator,像对普通 Web 应用一样对这些应用进行伸缩。
要了解更多内容,可以浏览 Github 仓库,在我们的社区中讨论。
FAQ
- Q:和 StatefulSet(从前的 PetSet)有什么区别?
A:有的应用需要集群提供“有状态资源”,例如静态 IP 或者存储,StatefulSet 让 Kubernetes 有了支持这种应用的能力。然而有的应用需要更多的有状态部署模型的支持,例如故障的告警和应对、备份、重新配置等。所以 Operator 应用可以根据部署特性需求来选择 StatefulSets 或者 ReplicaSets 以及 Deployments。
- Q:和 Chef、Puppet 这样的配置管理系统相比呢?
A:容器和 Kubernetes 的给了 Operator 生存基础。这两个技术让新软件的部署、分布式配置的协调、检查多主机系统状态等工作变得轻而易举。Operator 把这种种优势聚合在一起,为应用的用户提供方便;他提供的不仅仅是配置,还包括上线、状态等全部内容。
- Q:和 Helm 的区别?
A:Helm 是一个把多个 Kubernetes 资源包装为一个单独软件包的工具。把多个应用集成在一起的概念,可以和 Operator 的活动管理进行互补。例如 Traefik 是一个负载均衡,他可以使用 ETCD 作为后端数据库。可以创建一个 Helm Chart ,同时部署 Traefik 的 Deployment 对象以及 etcd 集群。也可以使用 etcd Operator 进行 etcd 集群的部署和管理。
- Q:这对于 Kubernetes 的新用户来说意味着什么?
A:这对新用户没什么影响,而且可以更简便的部署 etcd、Prometheus 这样的复杂应用,并且以后会有更多软件支持。我们推荐的试水方式是 minikube 以及 kubectl run,然后可以用
kubectl run启动 Prometheus Operator 来监控部署的应用。
- Q:etcd 和 Prometheus Operator 的代码开放了么?
A:是的,分别位于 https://github.com/coreos/etcd-operator 以及 https://github.com/coreos/prometheus-operator
- Q:是否有计划开发其他的 Operator?
A:未来会的。我们还希望社区能够更多参与,让我们也知道用户需要什么样的 Operator。
- Q:Operator 能够让集群更安全么?
A:无法更新的软件是一个常见的问题原因和安全隐患,Operator 能让用户更自信的进行升级,打破这一限制。
- Q:Operator 能够帮助进行灾难恢复么?
A:Operator 能够轻松地对应用进行阶段性备份以及恢复。我们还希望开发一个功能,让用户可以从备份开始安装新的实例。
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。