SoundCloud 如何使用 HAProxy 和 Kubernetes 处理用户流量
原文:How SoundCloud uses HAProxy with Kubernetes for user-facing traffic
两年前 SoundCloud 开始了将我们的自研部署平台 Bazooka 迁移到 Kubernetes 的尝试。Kubernetes 将容器化应用的部署、伸缩和管理都进行了自动化。
问题
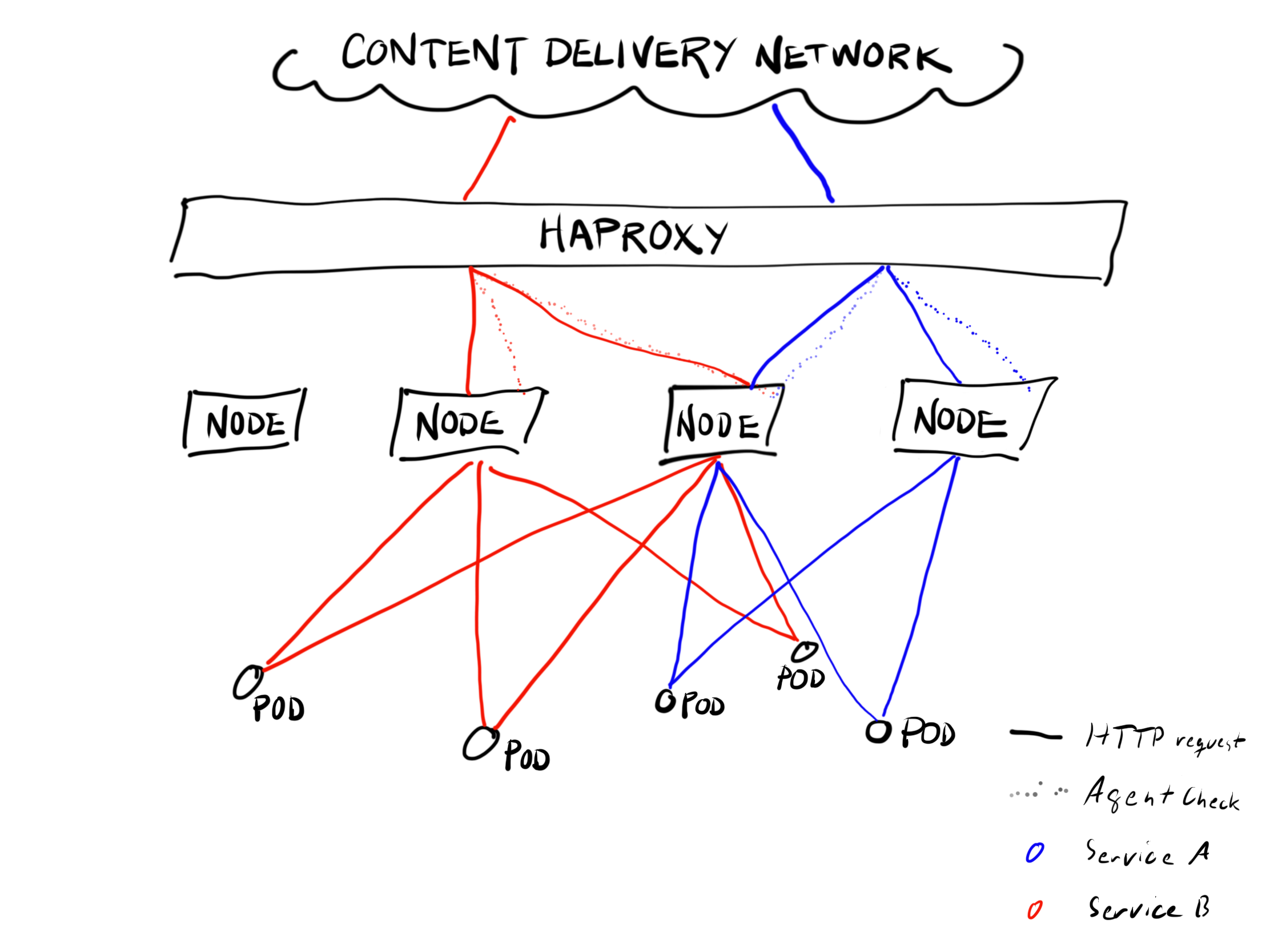
用户流量的路由,是这类动态平台需要面对的一个重大挑战:把来自用户的 API 和网站访问路由到运行在 Kubernetes 的 Pod 上。
多数 SoundCloud 运行在一个物理机环境下,所以我们无法享受 Kubernetes Loadblancer 的福利。在基础设施的边际,有一组 HAProxy 服务器使用简单的规则,承担着 SSL 端点的角色,把流量转发给各种内部服务。这些服务器的配置在运行之前是分别进行生成和测试的。有很多内置的保护措施的存在,这一过程会相当耗时,无法跟上 Kubernetes 集群中 Pod 的漂移速度。这样就导致我们的静态 SSL 端点和 Kubernetes 中的动态变化之间的矛盾。
过程
起初,我们把端点层配置为转发 HTTP 请求到 HAProxy 为基础的 Ingress Controller 之中,但是这一方案对我们不太合适,Ingress 控制器设计预期是低流量的内部服务,并不可靠。我们的用户生成了很多流量,每一个问题都会导致部分用户无法使用 SoundCloud。在 Kubernetes Ingress 和端点之间,我们有了两层 L7 要相互配对,而且经常无法配对。这对我们的开发人员造成很大困扰,增加了不少工作。
我们还知道 Ingress Controller 无法处理我们部分客户端使用的长连接。
当 SoundCloud 工程师构建应用时,我们使用一个自定义命令行界面来生成 Namespace、Service、Deployment 和可选的 Ingress Kubernetes 对象。我们添加了一个参数,来把服务改成 NodePort 类型,
Kubernetes 在集群中找一个没被占用的端口分配给服务,并在集群每个节点上开放这个端口。到任意一个节点的该端口的访问都会被转发给这一服务的某一个实例。(我们生成的 Kubernetes 对象在 Deployment 和 Service 之间有着一对一的关系)。为简便起见,这里就不深入谈论 ReplicaSet、Pod、以及 Endpoint 等 Kubernetes 对象了。
对服务的这种改变(Ingress 到 NodePort)是不可逆的。Kubernetes 不允许移除服务定义中的 NodePort 字段。我们还在寻求解决办法 —— 这种情况虽然可以通过删除再重建服务的方式来解决,但是这一方式会导致服务中断。
应用开发者为应用声明集群、命名空间、服务和端口名,生成一个特定的主机名和路径。系统根据这一配置,将来自 SSL 端点、CDN 分发以及 DNS 等的流量转发给应用。
实现
当端点配置声成以后,脚本向 Kubernetes 集群查询每个服务的 Node Port,以及 Kubernetes 的节点列表。起初我们把所有节点都加入到端点的配置之中,不过后来证明这是一个问题。
每个端点会独立的检查每个节点的每个端口的健康状况。几十个端点,几百个 Kubernetes 节点,导致每秒钟上万次的健康检查。这种检查是通过节点进行的,跟服务规模无关,所以即使是很低流量的服务,也需要大量的资源来应对这些健康检查。
我们因此减少了配置给每个服务的节点数量,不过我们也不希望这个节点数量太少,免得造成性能瓶颈。一个简单的方案就是随机从列表中选择一些节点,但这样的话,这一列表的每次生成,都会发生很大的变化,会跟真正的部署调整造成混淆。所以我们决定使用服务名称和节点地址来进行哈希,为每个服务选择一组固定数量的服务器,但是这个选择在节点不变的情况下也会保持不变。
我们选择足够多的节点,这样就不必担心一两台节点发生当机,或节点被多个高流量服务重叠使用。
要替换一个节点,只需要重启 Pipeline,生成并部署新的端点配置。这会花费几个小时,好在是全自动的。因为每个服务都通过有限数量的节点进行路由,因此不能一次性的从同一个服务中移除太多节点。这意味着,我们只能每天从 Kubernetes 集群中替换有限数量的节点,不过目前为止这还没有造成什么问题。
Node Agent
在短期维护中,例如内核更新需要重启节点,我们需要一种将节点优雅排空的能力。我们为 HAProxy 的 agent-check 协议开发了一个 Agent,监听每个节点的固定端口。为了简单起见,我们希望能够同时移除流量和 Pod,当节点从 Kubernetes 进行隔离之后,新的 Pod 不会被调度在这一节点上,Agent 更新 HAProxy 状态,将流量从这一节点上移除。
有时我们还要把流量在一个服务的不同 Deployment 之间进行切换,还包括同一集群和不同集群的情况。为了支持这种切换,我们对这个 Agent 进行了扩展。我们在 Kubernetes 的 Service 对象上增加了一些注解(annotations),以此指示监听新的端口,扩展的 Agent 不仅检查节点的维护状态,还会检查这一服务的优先级。端点配置过程会获取这一信息并据此配置 Agent 的检查行为。应用开发者可以添加多个 Kubernetes 后端到任意的公开主机和路径。每个后端我们都像之前一样利用哈希选择一组节点提供服务。修改服务注解,就能在几秒钟改变各个后端服务的权重。
未来
这种基于 NodePort 的路由方式工作的不错,但是也有一些隐忧。一个应用实例之间的负载分配并不均等,我们的应对方式是为应用分配稍多的资源。这一问题上,多分配资源的成本远低于由工程师开发新的负载均衡机制所需要的花费。
在物理机组成的数据中心运维 Kubernetes 是一个挑战。在公有云服务中,都会提供标准方案;而每个数据中心都会有些不同——尤其是并非从头开始,而是将 Kubernetes 向现有基础设施进行融合的情况下。本文中,我们主要阐述的就是我们应对部分问题的部分解决方法.
下一步?我们目前考虑的是在不同位置的多个 Kubernetes 集群,为不同用户选择不同集群来达到优化体验的目的。
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。