Google 宣布 Kubernetes Operator for Spark
作者:Andrew Brust
原文:Google announces Kubernetes Operator for Apache Spark
“Spark Operator” 的 Beta 版本,可以用来在 Kubernetes 上执行原生 Spark 应用,无需 Hadoop 或 Mesos。
Apache Spark是一个流行的执行框架,用于执行数据工程和机器学习方面的工作负载。他提供 Databricks 平台的支持,可用于内部部署的或者公有云的 Hadoop 服务,例如 Azure HDInsight、Amazon EMR、以及 Google Cloud Dataproc,也可以在 Mesos 集群上运行。
但是如果只是想在 Kubernetes(k8s) 而非 Mesos 上运行 Spark 工作负载,也不想使用 YARN,这可行么?Spark 在 2.3 版本中首次加入了针对 Kubernetes 的功能,并在 2.4 中进行了进一步增强,然而让 Spark 用全集成的方式原生运行在 Kubernetes 上,仍然是非常有挑战的。
Kube Operator
Kubernetes 的始作俑者 Google,宣布了 Kubernetes Operator for Apache Spark 的 Beta 版本,简称 Spark Operator。Spark Operator 让 Spark 可以原生运行在 Kubernetes 集群上。 Spark 应用(这些应用用于分析、数据工程或者机器学习)可以部署在这些集群上运行,像在其它集群上一样。
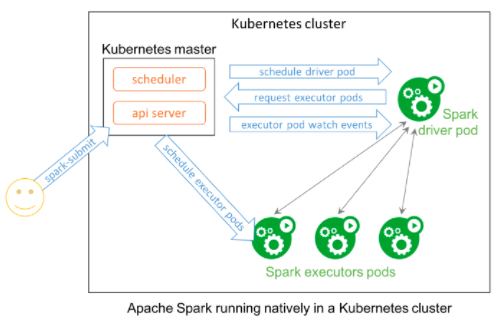
Google 声明,Spark Operator 是一个 Kubernetes 自定义控制器,其中使用自定义资源来声明 Spark 应用的元数据;它还支持自动重启动以及基于 cron 的计划任务。今后,开发者、数据工程师以及数据科学家可以创建声明式的规范,来描述他们的 Spark 应用,并使用原生的 Kubernetes 工具(例如 Kubectl)来管理他们的应用。
现在就试试
Spark Operator 目前在 GCP 的 Kubernetes 市场中已经可用,可以方便的部署到 Google Kubernetes Engine(GKE)。另外 Spark Operator 是一个开源项目,能够部署在任何 Kubernetes 环境中,项目的 Github 页面提供了基于 Helm Chart 的安装指南。
如果 Amazon 和微软这样的厂商任何并在自家的 Kubernetes 服务上(微软的 AKS 以及 Amazon 的 ECS)提供 Spark Operator 的部署方式,会是个有意思的局面。这对他们的客户来说会是一个很棒的服务,客户并不想要在 EMR、HDInsight 或者 Daabricks 的工作空间和集群上付出开销。
Hadoop 怎么办
很多非 Databricks 的 Spark 集群是运行在 Hadoop 上的。Spark Operators 的出现,是否意味着 Hadoop 的影响被削弱了?Hadoop 团队也并非游手好闲之辈,例如 开放混合架构草案就聚焦于 Hadoop 的容器化。另外上周发布的 Hadoop 3.2,其功能就包括了对 Tensorflow 的支持,Azure Data Lake Storage Gen2 的链接支持以及增强的Amazon S3 的增强支持。
消费者和往常一样,将在激烈的竞争中获益。
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。