在 Kubernetes 1.2 中使用 Spark 和 Zeppelin 处理大数据
原文:Using Spark and Zeppelin to process big data on Kubernetes 1.2
大数据应用与日俱增,很多 Kubernetes 用户希望利用 Kubernetes 集群来运行 Apache Spark,借助容器的能力来获得弹性和移植性。在 Kubernetes 1.2 中,为 Spark、Zeppelin 以及其他应用提供了协同工作的平台。
Zeppelin 是什么?
Apache Zeppelin 是一个基于 Web 的交互式数据分析工具。Spark 也是 Zeppelin 所支持的后台之一。在命令行交互以及 Scala 之外,Zeppelin 为用户提供了一种较为简易的和 Spark 集群交互的能力。
为什么用 Kubernetes?
有很多无需 Kubernetes 运行 Spark 的方式:
那么为什么在 Kubernetes 上运行 Spark ?
- 一个单纯的、统一的集群接口:Kubernetes 能够支撑多种负载;无需为 YARN/HDFS 和其他应用进行不同的编排。
- 提高服务器的利用率:在 Spark 和其他应用之间共享节点。你可以用一个串流应用来为 Spark 管线提供数据,也可以运行一个 Nginx Pod 来提供 Web 服务,无需对节点进行静态分区。
- 不同负载之间的隔离:Kubernetes 的 服务质量 (Quality of Service) 机制让用户能够安全的同时调度批处理应用(类似 Spark)以及延迟敏感的其他应用。
Spark 加载
这里使用 Google 容器引擎(GKE) 来进行演示,不过这些过程也适用于其他的 Kubernetes 集群。首先创建一个容器引擎的集群,并指定其 scope 为 storage-full。这样的设置允许该集群写入到私有的 Google 云存储中(我们会在后面解释这一选择的理由):
gcloud container clusters create spark --scopes storage-full --machine-type n1-standard-4
注意我们使用的类型是
n1-standard-4(比缺省的节点类型稍大),用来演示 Pod 的纵向扩展能力。然而 Spark 在缺省的n1-standard-1上也能够运行。
集群建立之后,就可以利用 Kubernetes Github 仓库中的配置文件来在集群中启动 Spark 了:
git clone https://github.com/kubernetes/kubernetes.git
kubectl create -f kubernetes/examples/spark
kubernetes/examples/spark 是一个目录,这一命令告诉 kubectl 创建这一目录下所有的 YAML 文件所定义的 Kubernetes 对象。
Pod(尤其是 Apache Zeppelin)很大,所以需要一些时间让 Docker 来拉取镜像,一旦运行成功,你会看到类似以下的输出:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spark-master-controller-v4v4y 1/1 Running 0 21h
spark-worker-controller-7phix 1/1 Running 0 21h
spark-worker-controller-hq9l9 1/1 Running 0 21h
spark-worker-controller-vwei5 1/1 Running 0 21h
zeppelin-controller-t1njl 1/1 Running 0 21h
可以看出 Kubernetes 正在运行一个 Zeppelin 实例,一个 Spark Master 以及三个 Spark worker。
设置 Zeppelin 的安全代理
接下来要设置一个从本机到 Zeppelin 的安全代理,以便从你的机器访问 Zeppelin 实例。(注意这里需要根据你集群中的 Zeppelin Pod 的实际名称修改这个命令)
$ kubectl port-forward zeppelin-controller-t1njl 8080:8080
这就建立了一个从 Kubernetes 集群到 Pod ( zeppelin-controller-t1njl ) 的安全连接,并把这个端口映射到本地的 8080 端口,让你可以安全的使用 Zeppelin。
对正在运行的 Zeppelin 做点什么?
例如我们将要演示如何创建一个简单的电影推荐模型。这一演示基于 Spark 网站提供的代码,为了演示 Kubernetes 的特性,做了一点修改。
现在安全代理启动了,浏览 http://localhost:8080/ 应该会看到下面的页面:
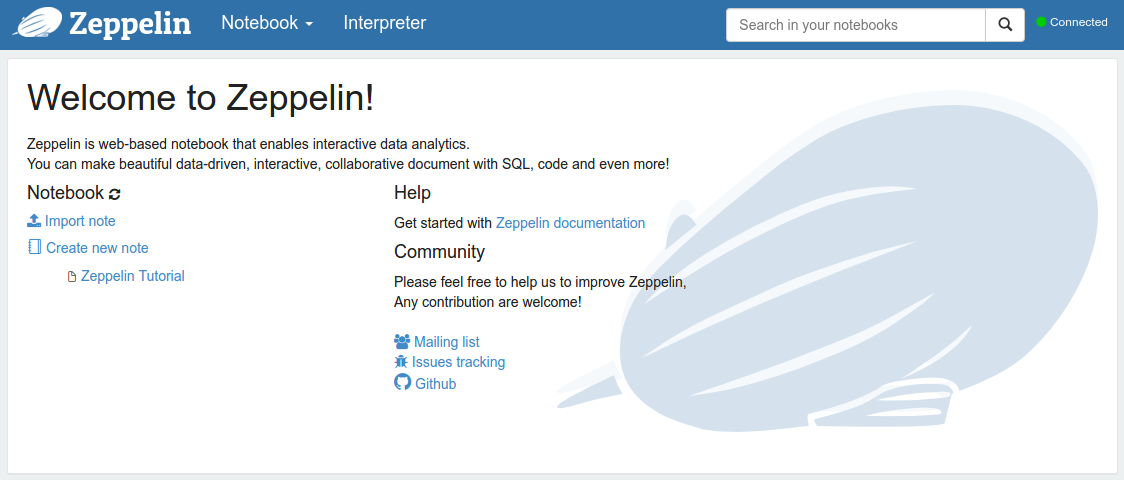
点击 “Import note”,设置一个随便什么名字(比如 “Movies”),点击 “Add from URL”,网址输入:
https://gist.githubusercontent.com/zmerlynn/875fed0f587d12b08ec9/raw/6
eac83e99caf712482a4937800b17bbd2e7b33c4/movies.json
然后点击 “Import Note”,就会获取到这个 Demo 所需的 Zeppelin note。现在我们就有了一个 Notebook,如果点击这个 Note,会看到下面的内容:
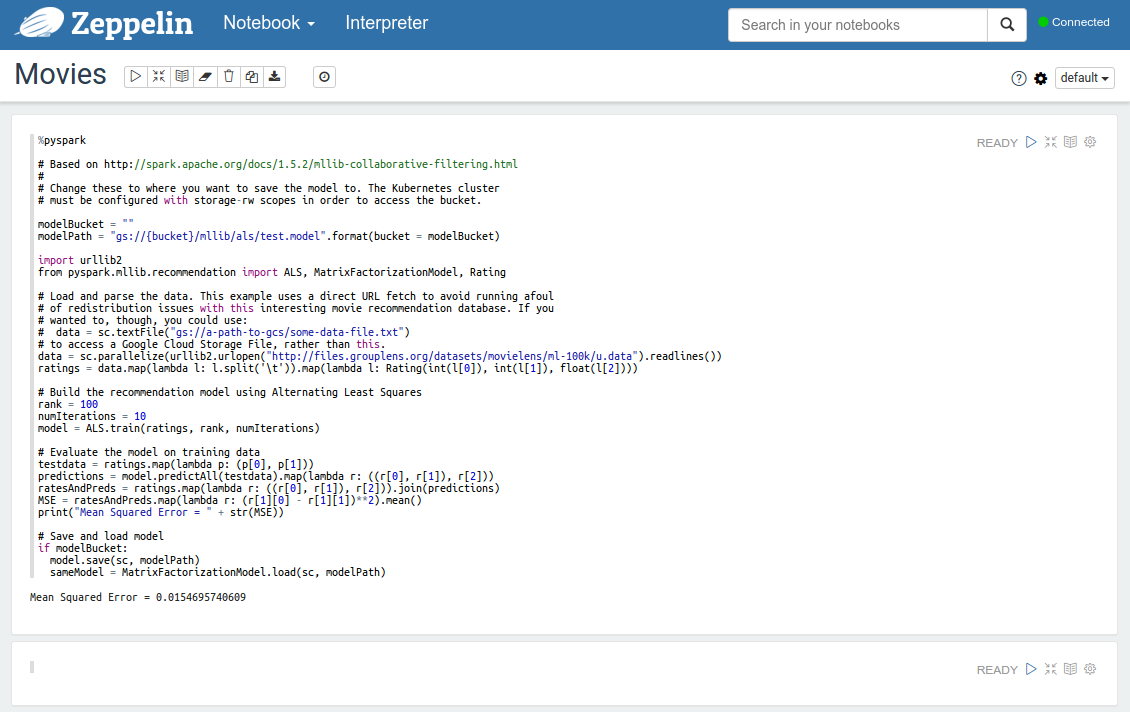
接下来可以点击右上角的 Play 按钮,就会创建一个新的电影推荐模型。在 Spark 应用模型中,Zeppelin 扮演 Spark Driver Program,他负责同 Spark 集群交互,并令集群完成任务。在这里 Zeppelin Pod 中的应用获取数据,并发送给 Spark Master,Master 将其分发给 Worker,这些 Worker 会利用 Zeppelin 提供的代码来生成一个电影推荐模型。在下一节中,我们将会讲讲向 GCS 存储数据的问题。
使用 Google 云存储(可选)
在这个演示中,我们将使用 Google 云存储来保存我们的模型数据,这样就可以避免 Pod 生命周期的限制了。Kubernetes 版本的 Spark 内置了 Google 云存储 的连接器。只要能够从运行着这个 Kubernetes 节点的 Google 容器引擎项目中能够访问到数据,那么同样的,你的 Spark 镜像也能利用 GCS 连接器访问数据。
还可以在 Note 中修改例子中的变量,就可以保存和恢复电影推荐引擎的模型了,只要把这些变量指向 你有权访问的 GCS Bucket 就可以了。如果要创建一个 GCS Bucket,需要执行下面类似的命令:
gsutil mb gs://my-spark-models
URL 部分可以按照用户自己的需要来指定,执行后会生成相应的 Bucket 供应用来使用。
注意:运行这一模型,然后保存,这一过程远比运行后丢弃要慢。这很正常,但是如果要复用一个模型,那么计算后保存,复用时恢复就要比每次重新运算要快了。
使用 Pod 的纵向扩展(可选)
Spark 的 Works 有一些弹性功能,这让我们有机会:用 Kubernetes Pod 纵向扩展能力 来对 Spark worker 池自动扩展,为 Work 设置一个目标 CPU 阈值以及最大最小规模即可。这样就不需手工配置 Worker 集群了。
下面就是创建自动伸缩的指令
注意:如果没有改变这一集群的机器类型,你可能需要把 –max 参数设置的小一点。
kubectl autoscale --min=1 --cpu-percent=80 --max=10 rc/spark-worker-controller
可以看到 Replication Controller 把实例数降低到 1,证明了自动伸缩的效果。使用 bubectl get rc,会看到 spark-worker-controller 的 “replicas” 这一列会落回到 1。
之前我们运行的负载太低。为了让任务运行更久一点,我们把 “rank = 100” 改成 “rank = 200”。这样在点击 “Play” 按钮后,Spark worker 会迅速增加到 20 pod,在工作完成后,最多需要五分钟,Work 池开始回落到单一实例。
结论
本文中我们展示了如何在 Kubernetes 中运行 Spark 和 Zeppelin,以及如何使用 Google 云存储来保存 Spark Model,还介绍了利用 Kubernetes 自动伸缩特性来动态设置 Spark worker 池。
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。