Medium 的微服务架构
作者:Xiao Ma
原文:Microservice Architecture at Medium
微服务架构的目标是帮助工程团队安全快速地完成高质量的产品交付。良好解耦的服务能够在最小化对其它系统的影响的条件下进行快速迭代。
2012 年构建的 Node.js 单体应用构成了 Medium 的最初技术栈。我们构建了各种卫星服务,但是并没有提出系统化采用微服务架构的策略。2018 年初,随着系统复杂性的提高和团队规模的扩大,我们开始转向了微服务架构,工作中总结出一些如何高效完成这一过程并避免微服务症候群的经验,本文将分享这一经验。
什么是微服务架构
首先我们花费一点时间来思考一下,微服务是什么/不是什么的问题。目前的软件工程有一些滥用和混乱的趋势,微服务就是其中一个。Medium 认为微服务是:
微服务架构中,多个松耦合的服务协同工作,每个服务聚焦于一个单一的目的,而这一目的相关的数据和行为则在单一服务内高度聚合。
这一定义中包含了微服务的三个设计原则:
- 单一目的:每个服务应该专注于做好一件事。
- 低耦合:服务之间极少互相了解。对一个服务的变更不应该要求其它服务也进行变更。服务之间的通信金应该发生在公开的服务接口之中。
- 高内聚:每个服务应该对所有相关的行为和数据进行封装。如果需要构建新的功能,所有的变更只应该落地到一个服务之中。
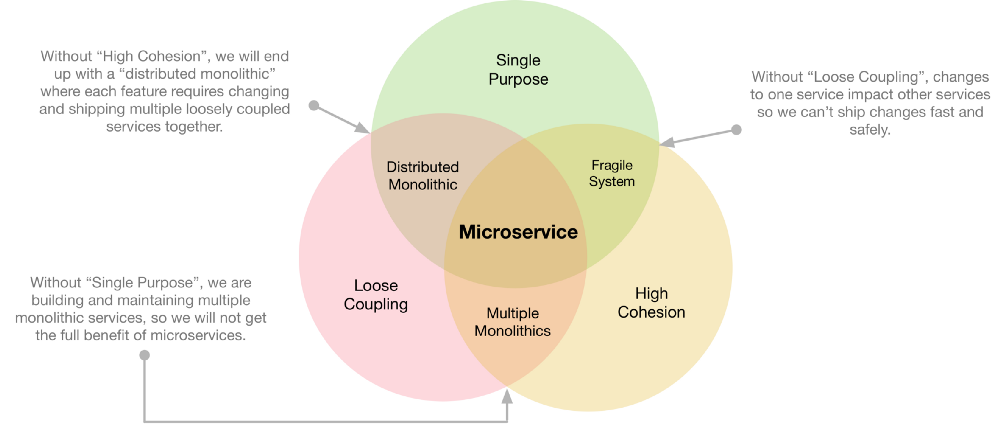
进行微服务建模的过程中使用应遵循这三条原则。这是释放微服务能量的唯一途径,违反任何一条,都会违反微服务模式的理念。
如果违反了目的单一性原则,每个微服务最终都会负担太多任务,成为多个单体服务。这无法获得微服务应有的好处,并且要付出更多的运维成本。
不遵守松耦合原则的后果是,一个服务的变更会影响到其它服务,所以也就无法快速安全的进行发布——这是微服务的核心优势。紧密耦合还可能造成数据冲突甚至丢失。
而如果缺乏内聚性,就会变成分布式的单体系统——为了完成一个功能修改,必须同时变更和部署一堆服务。分布式的单体系统经常比中心化的单体系统更加糟糕,多个服务甚至多个团队的协调过程造成更高的复杂度和成本消耗。
同时,微服务不是什么,也是个同样重要的问题。
- 微服务不一定是一个行数较少、或者完成细小任务的服务。显然,这一个误解是来自于微服务这个名字的。微服务架构的目标不是创建尽可能多的服务。符合上述三个原则的服务,可能结构复杂,可能规模庞大,也一样可以称之为微服务。
- 微服务不一定需要用最新的技术进行构建。虽说微服务架构让团队能够更方面的试水新技术,但这不是主要目标。用同样的技术构建所有新服务完全没有问题,团队同样能从服务解耦中获益。
- 微服务并不一定需要从头做起。如果已经有了一个架构良好的单体应用,应该避免从头构建所有新服务。可能会有机会对单体服务进行分拆。再一次提醒,上面的三个原则是应当坚守的。
为什么是现在
在 Medium 需要在产品或者工程方面作出重大决策时,经常会提出一个问题:为什么是现在?“为什么”是个很明显需要解决的问题,但这个问题的答案在假设我们有无穷的人力、时间和资源,很明显这是一个危险的假设。把这个问题改为“为什么是现在”,就突然出现了很多的制约——对现有工作的影响、机会成本、并行的开销等。这一问帮助我们更好的确定优先级。
为什么现在要使用微服务架构的原因就是——我们的 Node.js 单体应用在很多方面都成为了瓶颈。
首先最紧急和重要的瓶颈就是它的性能。有一些重度计算和重度 I/O 的任务并不适合 Node.js。我们一直在持续这一单体应用的改进工作,然而并无起色。低下的性能妨碍了产品改进工作——功能的改进可能让这个已经很慢的应用更加缓慢。
第二,一个重要且有点紧急的瓶颈就是单体应用拖慢了应用开发过程。所有的工程师都在单一的应用中构建功能,耦合在一起。因为可能存在的互相影响,我们没法轻松的对系统的某一方面做出变更。整个应用作为一个整体进行部署,所以如果一个不良提交导致了问题,那么这次部署中涉及的所有其它变更不论工作状况有多完美,都会受到拖累。而在微服务架构中,团队可以更快的交付、研究和迭代。正在构建的新功能会从其它复杂系统中解耦出来,让开发团队可以专注于此。所以新的变更能够更快的推向生产环境,从而具备了安全尝试变更的机会。
在我们新的微服务架构中,变更可以在一小时内发布到生产环境上,工程师不必担忧这些变更会对系统其它部分造成多大影响。团队还在探索在开发环境中安全使用生产数据的方法——这可是做了多年的白日梦。随着我们工程师团队的发展壮大,这些因素的重要性也日益提升。
第三,单体应用中,很难针对部分任务作出性能扩展,也很难针对不同类型的任务进行资源隔离。单体应用只能为整个系统进行伸缩,为了某个资源大户进行整体扩展之后,对系统中其它的相对简单任务来说,系统资源就处于超配状态了。为了缓解这一情况,我们将不同类型的请求发送给不同的 Node.js 进程。这种做法在某种程度上来说是有效的,但是伸缩一样受到限制,这还是因为单体应用的紧耦合特性造成的负担。
最后一点,也是同样重要的一点。一个即将浮上水面的问题就是单体应用阻止了对新技术的尝试。微服务架构的一个主要优势就在于每个服务可以使用不同的技术栈进行构建,将不同的技术进行整合。微服务架构让我们可以为特定工作选择最优方案,更重要的是,可以更快更安全的完成任务。
微服务策略
微服务之路并非一帆风顺,一旦误入歧途就会对生产力造成损害。本节中我们会分享七条策略,这些策略在我们进入微服务架构的初期给了我们很大帮助。
- 构建具备清晰价值的新服务。
- 单一的持久存储是有害的。
- 服务的构建和运行应该解耦。
- 详尽、一致的可观察性。
- 无需从头构建每个新服务。
- 故障总会发生,必须正视。
- 从第一天开始预防微服务综合症。
构建具备清晰价值的新服务
可能有人认为采用新的服务架构意味着产品开发的一个暂停,并且需要重写所有东西。这是一种错误方法。我们决不应该为了构建新服务而构建新服务。每次我们构建新服务或者采纳新技术,都必须有明确的业务价值或工程价值。
我们能交给用户的益处,就是业务价值的体现。相对我们的单体 Node.js 应用而言,新服务应该能够提供更多价值,或者更快的提供价值。工程价值就是让工程团队能够更好更快的工作。
如果一个新服务并不具备清晰的价值,我们就会把它留在单体应用中。十年之后 Medium 仍然有单体的 Nodejs 应用在服役也并不是什么大不了的事情。从一个单体应用开始,实际上让我们能够更有策略的进行微服务建模。
单一的持久存储是有害的
建模微服务的一大部分工作就是对持久化数据存储进行建模。要把微服务整合在一起,共享数据存储看起来是个最方便的做法。事实上这种做法是有害的,我们应该不惜一切代价来避免这种情况。下面解释一下原因。
首先持久化数据存储事关实现细节。在服务之间共享数据存储就相当于将服务实现的细节暴露给整个系统。如果这个服务修改了数据的格式,或者加入缓存层,又或者更换了不同的数据库,那么很多服务都必须跟进。这违反了松耦合原则。
其次,持久化数据存储的过程,例如修改、处理和使用数据的方法,并不是服务行为。如果我们在不同服务之间共享数据存储,就意味着其它服务也要复制服务行为。这样就违反了高内聚原则。特定领域的行为被泄漏到多个服务之中。修改了一个行为,就必须修改所有相关其它服务。
微服务架构中,特定类型的数据只应该由单一的服务负责。所有其它服务要使用这些数据只有两个选择,一是通过 API 向负责的服务发出请求;二是持有一个只读的非权威拷贝。
这听起来可能有点抽象,下面提供一个具体的例子。假设我们正构建一个新的推荐服务,这一服务需要一些来自发帖数据表中的数据,这些数据目前保存在 AWS DynamoDB 中。我们可以用两种方式把发帖数据提供给新的推荐服务。
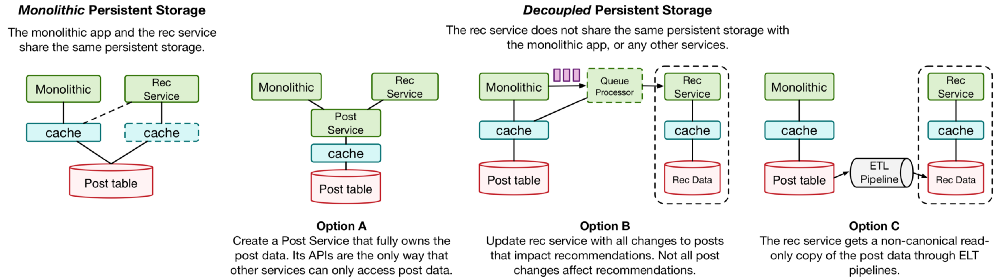
在单体存储模型中,推荐服务能够直接访问单体应用的持久化数据。这办法不太好:
- 缓存是个麻烦。如果推荐服务共享单体应用的缓存,我们就必须在推荐服务中复制缓存的实现细节;如果推荐服务使用自己的缓存,又无法在单体应用更新发帖数据时进行缓存失效。
- 如果单体应用决定用 RDS 替代 DynamoDB 进行发帖数据的存储,我们就必须重新在推荐服务中实现一次,当然所有其它共享这一数据的服务都要重来一次。
- 单体应用中处理发帖数据的逻辑比较复杂,例如如何决定一篇帖子是否可以显示给特定用户。我们必须在推荐服务中重新实现这些逻辑。一旦单体应用修改或者添加了新的逻辑,我们也必须在所有相关服务中重新实现。
- 不管推荐服务的访问模型如何,它也只能使用 DynamoDB。
在解耦存储模型中,推荐服务和其它新服务都没有直接访问发帖数据的能力。发帖数据的实现细节只存在于单一的服务中,有不同的方式可以实现这一目标。
理想情况下,应该又一个发帖服务作为发帖数据的所有者,其它服务职能通过这一服务的 API 来访问发帖数据。然而为所有的核心数据模型构建新服务可能需要高昂的成本。
在无法采用最佳方案的情况下,还有有两种行之有效的替代方案。视乎不同的数据访问模式,这可能是更实际的方法。选项 B 中,单体应用在相关帖子的数据更新时会通知推荐服务。通常这种操作的时效性要求不高,可以交给队列系统来完成。选项 C 中用 ETL 管道为推荐服务生成了一个帖子数据的只读拷贝,还加入了一些其它潜在可能对推荐服务有用的数据。两种方案里,推荐服务都完全控制了数据,所以它也就具备了正确处理缓存的能力、以及选择合适数据库的自由。
服务的构建和运行应该解耦
如果说服务构建困难重重的话,服务运行更是难上加难。如果服务的构建和运行耦合在一起的话,会拖慢工程团队,团队必须进行重复实现运行机制。我们希望每个服务能够专注于自身工作,无需担忧运行服务的复杂性,其中包括网络、通信协议、部署、监控等。服务管理应该完全从每个独立服务的实现中解耦出来。
服务构建和运行的解耦策略,应该是独立的,并且不依赖于特定的服务实现技术,这样应用工程师能够完全投入到各自服务的业务实现之中。
感谢近年来出现的容器化、容器编排、服务网格、APM 等进步技术,服务运行的解耦比过去任何时候都更加容易实现。
网络:网络(例如服务发现、路由、负载均衡、流量路由等)是服务运行的一个重要因素。传统的方式是为每个平台或者语言都提供库。这是有效的方法,但是不够理想,服务还是需要进行大量工作来完成这些库的集成和管理。有时候应用还要单独实现一些逻辑。现代的解决方案就是在服务网格中运行服务,Medium 使用了 Istio 和 Envoy 的 Sidecar 方案。构建服务的工程师完全不需要担心网络问题了。
通讯协议:不管用什么语言或者技术栈来构建微服务,选择一个成熟、高效、典型、跨平台并无需大量开发投入的 RPC 方案都是至关重要的。支持向后兼容的 RPC 方案让部署更加安全。Medium 选择了 gRPC。
一个常见的替代方案就是通过 HTTP 实现的 REST+JSON,这个方案在服务通讯领域流行已久。然而虽然这一方案对浏览器和服务器之间的通信很有效,但是对于服务间通信却有些不足,尤其是在发生大量请求的情况下。如果没有自动生成的 Stub 和模板代码,就只能手工实现服务端和客户端代码了。可靠的 RPC 实现不只是封装一个网络客户端。另外虽然 REST 很完备,但是有些细节并不能获得所有人的一致认同。例如一次调用,到底是 REST 还是 RPC?一条消息到底是一个资源还是一个操作?等等。
部署:有稳定的方式来构建、测试、打包、部署和管理服务是非常重要的。Medium 的微服务都运行在容器中。目前我们的系统是 AWS ECS 和 Kubernetes 的混合架构,正在向全 Kubernetes 迁移。
我们构建了我们自己的系统,称为 BBFD,用来完成构建、测试、打包和部署服务。在保证对不同服务的一视同仁和让各个服务可以使用各自的技术栈的弹性之间取得了一个平衡。每个服务只要提供一些基础信息,例如监听端口、用用构建、测试和运行服务的命令等。BBFD 会完成其它工作。
详尽、一致的可观察性
可观察性中包含了过程、方法和工具,让我们能够了解系统的工作状况,并在故障期间对问题进行鉴别。日志、性能跟踪、指标、Dashboard、告警都是可观察性的组成部分,它是能够左右微服务架构成败的关键因素。
我们从单体服务向多服务构成的分布式系统迁移的过程中,会发生两件事情:
- 丢失了可观察性——因为它的难度提高了,且更容易被忽视。
- 不同团队都在重新发明轮子,最终导致可观察性呈现为一种碎片状态,这实际上就降低了可观测性,很难用这些碎片数据来对问题进行关联或鉴别。
从一开始就应该建立良好的持续的可观察性,因此我们的 DevOps 团队提出了一致观察性的策略,并构建工具达成这一目标。每个服务都有详细的 DataDog Dashboard、告警和统一的日志搜索支持。我们还深度使用 LightStep 来进行系统性能方面的分析。
无需从头构建每个新服务。
微服务架构中,每个服务的任务都是专注做好自己的事情。这里对如何服务的构建方式并无要求。如果正在从单体应用向微服务架构进行迁移,一个需要注意的问题就是,如果能够从单体应用中剥出目标服务,那么可能并不一定需要从头进行构建。
针对是否需要从头构建新服务的问题,我们从务实的角度触发,主要考虑了两方面的问题:
- Node.js 是否适合新服务的需求。
- 用新的技术栈重新实现的成本如何。
如果 Node.js 是一个合适的选型,并且已有的实现并无不妥,我们就会从单体应用中抽取相关代码,以此作为基础来构建新服务。这样一来,虽然用的是既有实现,同样能够享受到微服务架构的益处。
我们的 Node.js 单体应用的架构让我们能够比较方便的抽取代码进行新服务的构建。后面我们还会讨论一下如何正确的构建一个单体应用的问题。
故障总会发生,必须正视
分布式环境中可能包含更多的故障机会。关键服务的故障如果不能及时处理,可能演变成一场灾难。我们应该随时思考如何完成故障的检测和处理。
- 第一也是最重要的,应该意识到所有一切都会在某个点上发生故障。
- RPC 调用尤其需要对故障案例进行着重处理。
- 确保系统故障情况下的可观测性(上面刚有提及)。
- 新服务上线之前必须针对故障进行测试,故障应对是新服务的 Check List 的一部分。
- 尽可能构建自动恢复功能。
从第一天开始预防微服务综合症。
微服务不是万金油,在解决一些问题的同时,也产生了被称为微服务综合症的新问题。如果我们不从一开始就考虑这个问题,事情有可能变得很麻烦,处理起来也要付出更多代价。下面列出一些常见症状。
- 建模粗糙的微服务危害巨大,尤其是在数量较多的情况下。
- 引入太多不同的语言和技术,会导致运维成本升高,分化工程团队。
- 服务构建和运行相耦合,会导致复杂度的急剧升高并拖慢工程进度。
- 忽略数据建模,导致单体数据存储形式的微服务。
- 缺乏可观测性,致使性能问题和故障难于定位。
- 面对问题时,团队可能选择创建新服务,而不是解决问题——即使解决问题是一个更好的选择。
- 缺乏整体视图的松耦合服务群本身就是一个问题。
是否不该构建单体服务
受益于近期的技术革新,使用微服务架构变得容易了很多。这是否意味着我们应该完全杜绝单体服务的构建了?
不是的。虽说新技术给了微服务更好的支持,但是微服务架构始终是更难更复杂的。对于刚起步的小团队,单体应用依旧是一个更好的选项。然而可以尝试对单体应用架构进行更好的设计,从而降低未来转向微服务架构时所需的投入。
从单体架构起步没什么问题,但是要保证系统的模块化,并按照上面的三个要素(单一目标、松耦合、高内聚)进行架构设计,最终构建成为一组技术栈一致、同步部署并且运行在同一个进程内的服务。
我们在 Medium 就在早期为单体应用做出了一些好的架构决策。
我们的单体应用由高度模块化的组件构成,最终成长为包含 Web Server、后端服务和离线时间处理器的庞然大物。离线处理器单独运行,但是试用了同样的代码。这样就能够相对简单的将业务逻辑抽取出来成为新的服务,新服务能够和之前的实现提供同样的(高级)接口。
我们的单体应用在较低层次对数据存储进行了封装。每个数据类型(一个数据库表)都有两层实现:数据层和服务层。
- 数据层为特定类型的数据提供 CRUD 操作的实现。
- 服务层处理特定类型数据的高级逻辑,并为系统的其余部分提供共用 API。服务之间不进行数据存储的共享。
数据的实现细节对其它部分的代码是完全隐藏的,这种做法帮助我们更好的进行微服务架构的迁移。创建新服务来处理某种数据相对来说是比较轻松和安全的。
单体应用还帮助我们对微服务进行建模,并让我们可以无需从头做起,而是专注在系统的最重要部分上进行微服务的迁移。
结语
多年以来,我们的单体 Node.js 应用发挥了巨大作用,然而对于大项目的交付和快速迭代的要求,开始力不从心,所以我们开始系统地、策略地转向微服务架构。我们的探索才刚刚开始,但是已经看到了它的好处和潜力——它戏剧性的提高了开发生产力、让我们可以从大处着眼并对产品做出大规模的改进,同时工程团队得到解放,能够安全的测试新的技术。