如何从单体应用中拆分富数据服务
原文:How to extract a data-rich service from a monolith
关于作者:Praful Todkar 是 ThoughtWorks 的首席顾问,专门构建大型分布式商业软件系统。软件的构建过程中,他乐于在尽快实现商业价值的目标下,为复杂问题创建简单、优雅的解决方案。
在将单体应用拆分为较小服务的过程中,最难的部分就是单体服务数据库中的数据拆分。要进行这样的拆分,保证数据有一个全程唯一的写拷贝,并且遵循一系列步骤是很有帮助的。拆分步骤从对现有单体应用的逻辑分割开始:将服务行为拆分为一个单独的模块,然后把数据拆分到单独的数据表中。一系列动作之后,这些元素最终成为一个自治的新服务。
从单体应用向较小服务的迁移是目前的主流趋势。投资进行这样的迁移,其动力在于,围绕业务能力构建较小服务,能够提高开发者的生产力。团队一旦成为服务的主人,同时也就成为自身命运的主人,这就意味着可以不受系统中其他服务的限制,自由的对自有服务进行改善和升级。
这个转换过程之中最难的部分,就是从单体应用所持有的数据库中把新服务所属的数据拆分出来。如果从单体应用中拆分出来的逻辑部分仍然连接到同一个数据库,这种拆分无疑是比较简单的。但是这样一来,数据库就成为跨应用共享数据库,整个系统所呈现出的各自独立的分布式形态仅是徒有其表,在数据库层面,这依旧是一个紧耦合系统。真正独立的服务需要有独立的数据库——格式和数据都专属于服务。
本文中要讲述一系列步骤组成的一个解构模式,用来在最小化业务中断的前提下,从单体应用中拆出富数据服务。
服务拆分过程的指导原则
深入探讨之前,我想首先介绍两个对于服务拆分具有重要指导意义的基本原则。这两条原则能把从单体应用到多服务的拆分过程变得更加平滑,也更加安全。
整个迁移过程中,数据保持有单一的写拷贝
在转移过程中,我们应该保证待迁出服务的数据始终有一个单独的写拷贝。如果出现了多个可写拷贝,就会出现写冲突的风险。当多个客户端同时写入同一块数据的时候,写冲突就会出现。写冲突的应对是比较复杂的——需要选择一个处理模式,并进行相应的处理。例如以最后写入为准的话,会给部分客户端带来意料之外的后果,同时还要通知写入失败的客户端进行相应的纠错处理。这样的逻辑无疑是比较复杂的,应该尽量避免。
这里的服务拆分模式会保证在服务拆分过程中的任意时间点上,都保持唯一的可写副本,从而避免写冲突造成的复杂性。
遵循“架构演进原子化”的原则
我的同事 Zhamak Dehghani 提出一个原则,叫架构演进原子化,代表在架构迁移过程中使用一系列原子化步骤。这些步骤完成以后,架构就完成了承诺的升级。如果这些步骤没有完全执行,那么这一架构的状态会比初始状态更加糟糕。例如决定分拆一个服务,结果最后只拆分了逻辑,没能拆分数据,这样收获的是一个数据库层耦合的状态,这一状态依然会导致开发和运行时的紧密耦合。实际上对比开始分拆之前,系统变得更加复杂,开发和除错的难度也随之增加了。
下面讲到的模式中,我们建议完成其中的所有步骤来完成拆分工作。服务分拆过程之中的最大障碍并非来自技术,而是如何让既有的单体应用客户迁移到新的服务之中去。我们将在第五步讨论这一话题。
服务拆分的步骤
现在让我们进入实际的服务拆分模式之中。为了方便讲述和操作,我们会做一个例子,来解释服务拆分的具体过程。
假设有个单体形态的商品信息系统,用来给我们的电商平台提供商品信息。经过一段时间的发展和演进,这一系统的服务范围不仅包含了商品名称、类目名称等核心信息和相关逻辑,同时还包含了商品定价方面的逻辑和数据。商品核心信息和价格信息之间并没有清晰的边界。
另外系统的变动频率来看,价格方面的系统变更频率要远高于核心信息部分。数据访问的模式也是各有千秋。商品的价格信息变动比核心商品属性同样要快得多。这样一来,把价格部分分拆到单体应用之外,形成一个单独的服务就是个非常有吸引力的想法了。
同商品核心信息相比,价格信息更加适合分拆,这是因为在原有应用的依赖体系中,定价功能是一个叶子节点。核心商品信息被很多其他功能所依赖,例如商品库存、市场等很多功能。如果将核心信息功能分拆出来,就意味着同时要触动很多相关系统,这会产生很大的风险。因此应该在功能依赖图中选择一个有业务价值的叶子节点作为开始。
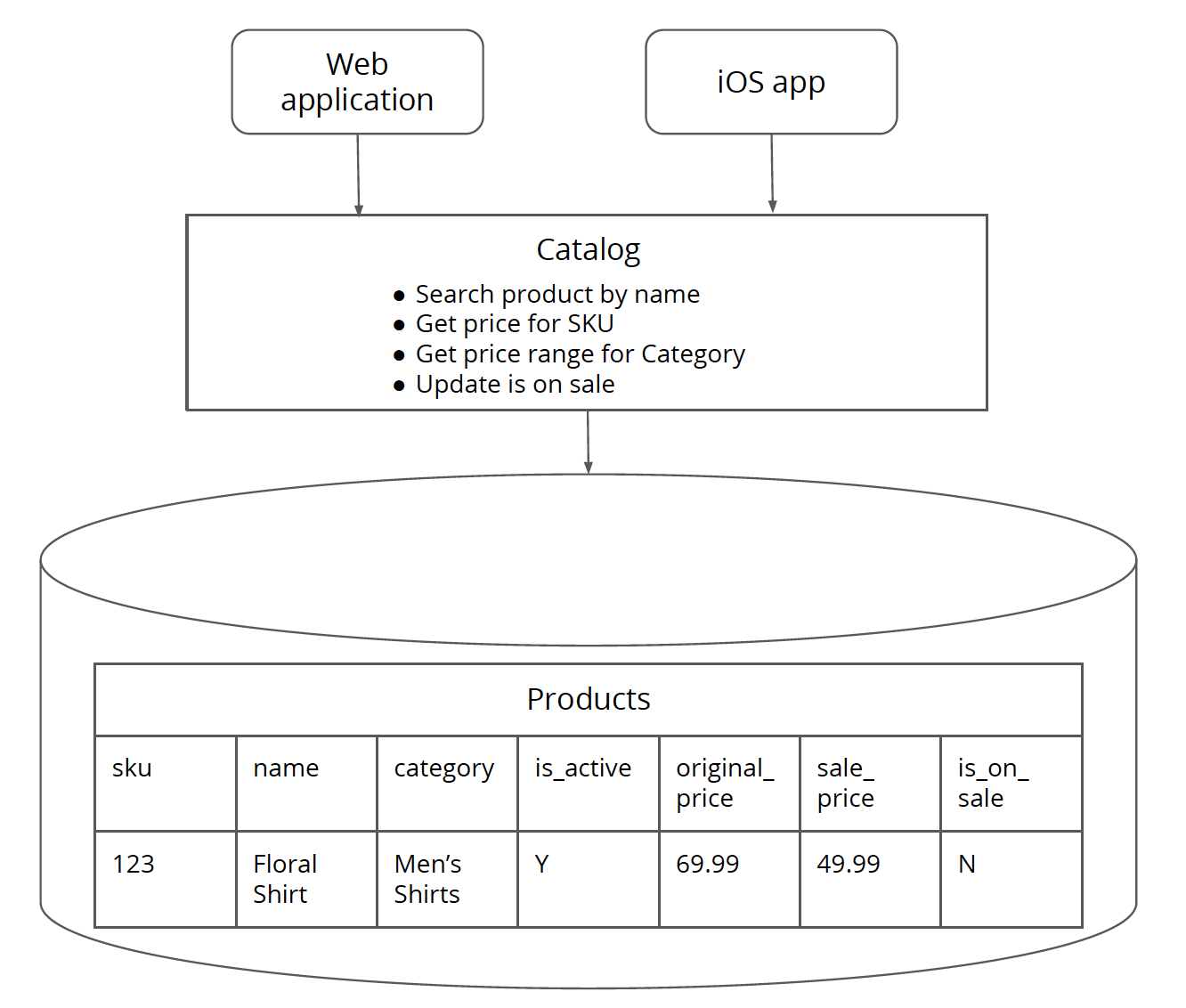
图 1:类目系统中包含了核心信息和价格信息两部分的逻辑和数据。有两个客户端——Web 应用和 iOS app。
代码的初始状态
下面是商品系统的现有代码。很明显的,这些代码不具备真实的复杂度。然而用来演示拆分富数据服务的重构过程,其复杂度还是足够的。下面的内容中会看到每个步骤中代码的变化过程。
这段代码中包含了一个 CatalogService 接口,用于给客户端提供服务。它使用一个 productRepository 类和数据库进行交互,用于数据的获取和存储。Product 是一个(Dumb data class)哑类,包含了商品信息。哑类设计是一种反模式设计,不过这不是本文的重点。Sku、Price 以及 CategoryPriceRange 几个类都是比较边缘的小类。
class CatalogService…
public Sku searchProduct(String searchString) {
return productRepository.searchProduct(searchString);
}
public Price getPriceFor(Sku sku) {
Product product = productRepository.queryProduct(sku);
return calculatePriceFor(product);
}
private Price calculatePriceFor(Product product) {
if(product.isOnSale()) return product.getSalePrice();
return product.getOriginalPrice();
}
public CategoryPriceRange getPriceRangeFor(Category category) {
List<Product> products = productRepository.findProductsFor(category);
Price maxPrice = null;
Price minPrice = null;
for (Product product : products) {
if (product.isActive()) {
Price productPrice = calculatePriceFor(product);
if (maxPrice == null || productPrice.isGreaterThan(maxPrice)) {
maxPrice = productPrice;
}
if (minPrice == null || productPrice.isLesserThan(minPrice)) {
minPrice = productPrice;
}
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
public void updateIsOnSaleFor(Sku sku) {
final Product product = productRepository.queryProduct(sku);
product.setOnSale(true);
productRepository.save(product);
}
下面就开始从商品单体应用中抽取 “Product pricing” 服务的第一步。
步骤 1:识别新服务涉及到的逻辑和数据
第一个步骤中,需要对商品应用中的商品定价服务所包含的逻辑和数据进行识别。我们的商品应用中包含了一个 Products 数据表,其中包含了 name、SKU、category_name 以及 is_active 标志(用于表示该商品是否有效或者已经弃用)等核心数据。每个商品都属于一个商品类目,类目就是一组商品。例如“男式衬衫”类目包含了花衬衫和晚礼服衬衫等商品。同时这个应用中还有一些核心的商品逻辑,例如根据名称进行商品搜索等。
Products 数据表还有一些定价相关的字段,例如 original_price、sale_price 以及 is_on_sale 标志(用于标识该商品是否在售)。商品应用中包含了一些定价方面的功能,比如计算商品价格、更新 is_on_sale 标志。另外还有一个纠结的功能,就是获取一个类目的价格区间,它主要属于定价范畴,但是也要涉及一些商品的核心功能。
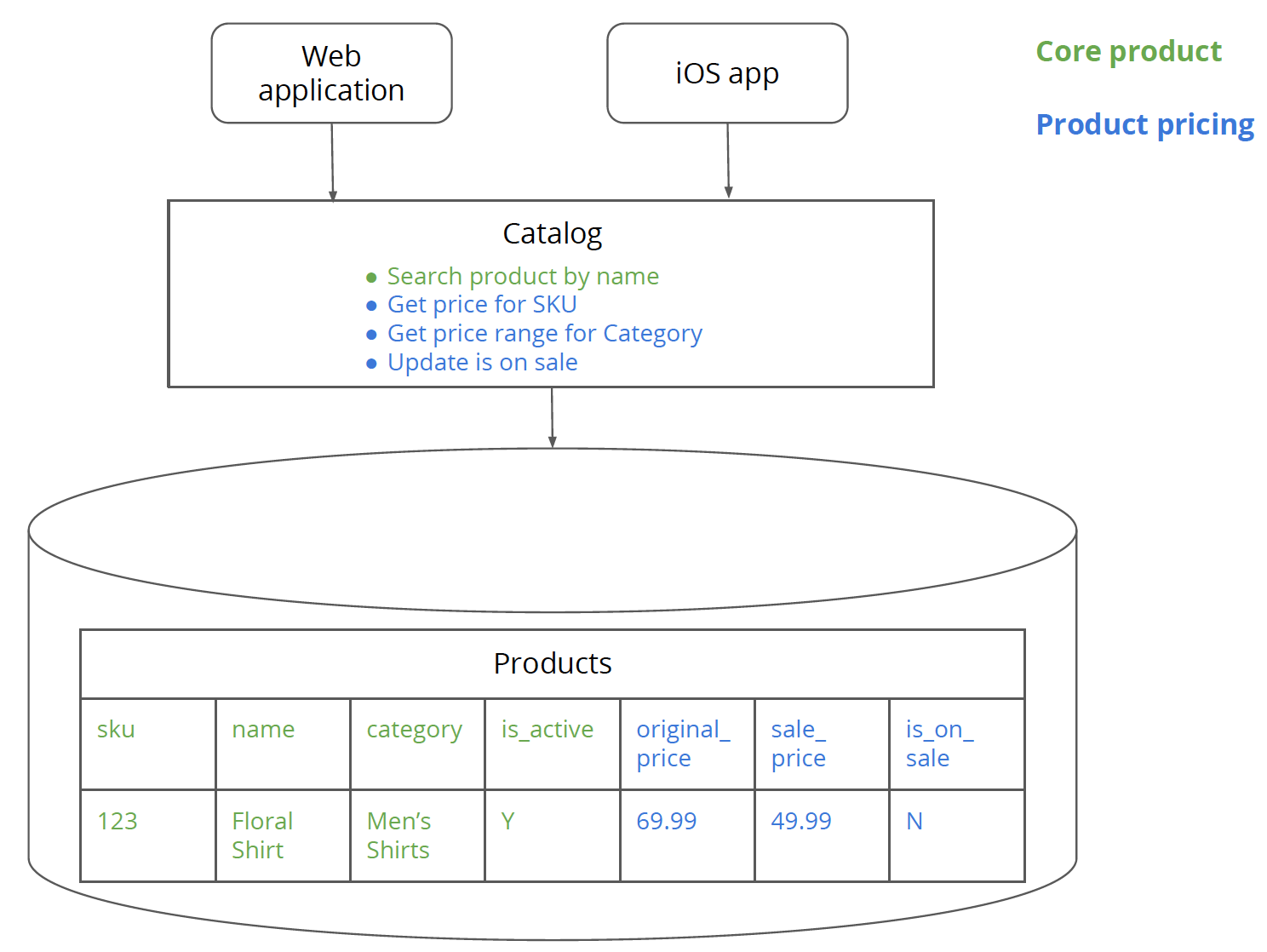
图 2:绿色部分是商品的核心逻辑和数据,蓝色部分是定价方面的逻辑和数据。
接下来重新贴一下上面的代码,代码没有发生变化,核心部分加入了注释(原文用蓝绿标识,MD 格式限制,只能用注释代替)。
// 搜索商品
public Sku searchProduct(String searchString) {
return productRepository.searchProduct(searchString);
}
public Price getPriceFor(Sku sku) {
Product product = productRepository.queryProduct(sku);
return calculatePriceFor(product);
}
private Price calculatePriceFor(Product product) {
if(product.isOnSale()) return product.getSalePrice();
return product.getOriginalPrice();
}
public CategoryPriceRange getPriceRangeFor(Category category) {
// 搜索指定类目中的商品
List<Product> products = productRepository.findProductsFor(category);
Price maxPrice = null;
Price minPrice = null;
for (Product product : products) {
// 商品是否可用
if (product.isActive()) {
Price productPrice = calculatePriceFor(product);
if (maxPrice == null || productPrice.isGreaterThan(maxPrice)) {
maxPrice = productPrice;
}
if (minPrice == null || productPrice.isLesserThan(minPrice)) {
minPrice = productPrice;
}
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
public void updateIsOnSaleFor(Sku sku) {
final Product product = productRepository.queryProduct(sku);
product.setOnSale(true);
productRepository.save(product);
}
步骤 2:在单体应用中对新服务进行逻辑上的拆分
第二三步是关于逻辑拆分的,要在商品应用持续运作的情况下,对商品定价服务的逻辑和数据进行逻辑上的分割。简而言之就是在创建新服务之前,首先在单体应用中,对产品的定价数据和逻辑进行隔离。这样做的好处在于,由于还在同一个代码库中,如果定错了产品定价服务所包含的逻辑或者数据边界,纠正这一错误所需的重构工作,相对于拆分为新服务之后,会比较简单一些。
第二步的一部分,我们要创建两个服务类,用来封装不同对象的逻辑:
- 商品核心类:
CoreProductService - 商品定价类:
ProductPricingService
这些服务类会和我们的“物理”类一一对应,也就是后面看到的商品定价和商品核心。我们还会创建独立的存储类—— ProductPriceRepository 用来访问产品定价数据,以及 CoreProductRepository 用来访问核心商品数据,这两种数据目前都存储在 Products 数据表中。
这部分工作中,需要时刻注意的关键一点是 ProductPricingService 或者 ProductPriceRepository 不应该访问 Products 表中的商品核心信息,而应该通过 CoreProductService 类来进行所有商品核心信息相关的访问。下文中会看到对 getPriceRangeFor 方法进行重构的例子。
不允许存在商品核心信息和商品定价信息之间的表关联。类似的,数据库中也不该有核心商品信息和商品定价信息之间的硬约束。所有的 JOIN 和 约束都应该从数据库层转移到逻辑层。不过知易行难是个普遍规律,数据库的拆分过程中,这一点是个难度和必要性都很高的任务。
不难看出,商品核心和商品定价之间是有一个共享的标识符的——两个系统中,SKU 都能能够作为商品的唯一标识。这种跨系统标识符会用在跨系统的通信过程之中,它的重要性显而易见,因此必须慎重选择。只能够有一个系统独立掌握这一数据。所有其它服务都只能对其进行只读的引用——在这些服务的视角中,标识符是固定不变的。标识符所属的实体,其生命周期的管理者,是最适合作为该标识符的属主的。例如我们的案例中,商品核心信息服务掌控着商品的生命周期,因此 SKU 标识符也应该由这一部分进行管理。
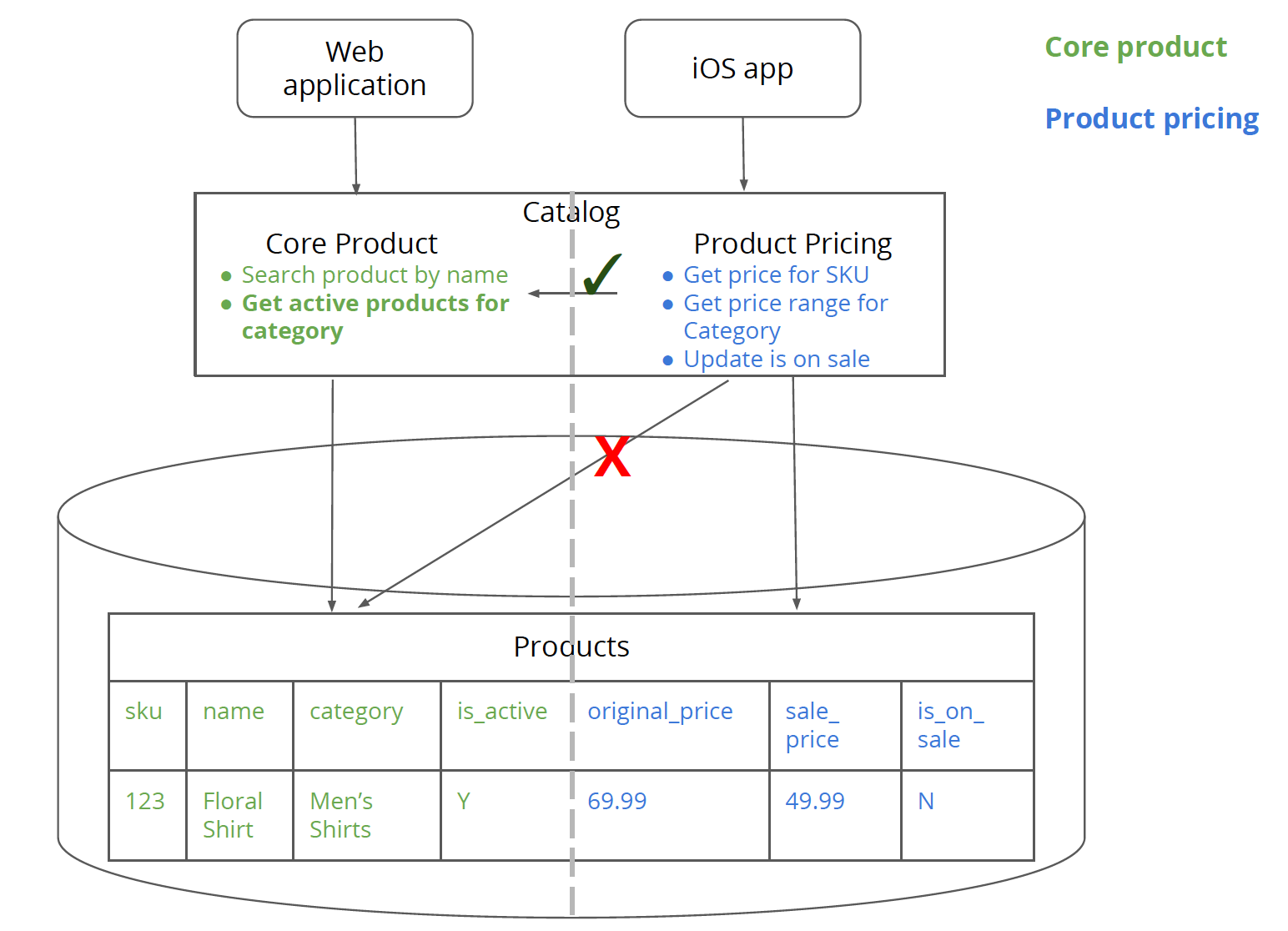
图 3:商品核心信息逻辑和商品定价逻辑的拆分,此时商品定价逻辑仍然连接在同一个商品数据表上。
下面是重构的代码。你会看到新建了 ProductPricingService 用来负责定价相关的逻辑。另外还定义了 productPriceRepository 用来访问 Products 表中的定价相关数据。现在的 Product 数据类被分为了 CoreProduct 和 ProductPrice 两个类,分别用户处理商品核心信息和商品定价信息。
class ProductPricingService…
public Price getPriceFor(Sku sku) {
ProductPrice productPrice = productPriceRepository.getPriceFor(sku);
return calculatePriceFor(productPrice);
}
private Price calculatePriceFor(ProductPrice productPrice) {
if(productPrice.isOnSale()) return productPrice.getSalePrice();
return productPrice.getOriginalPrice();
}
获取指定类目的价格范围,这一功能相对复杂。这是因为它需要获取类目中的商品列表,而这一操作是属于商品核心部分的。getPriceRangeFor 方法首先要调用 coreProductService 的 getActiveProductsFor 方法来获取类目中的有效商品列表。前面提到过 is_active 是商品核心的属性,因此将 isActive 检查也放到 coreProductService 之中。
class ProductPricingService…
public CategoryPriceRange getPriceRangeFor(Category category) {
// 获取商品列表
List<CoreProduct> products = coreProductService.getActiveProductsFor(category);
// 根据商品列表获取价格
List<ProductPrice> productPrices = productPriceRepository.getProductPricesFor(mapCoreProductToSku(products));
Price maxPrice = null;
Price minPrice = null;
for (ProductPrice productPrice : productPrices) {
Price currentProductPrice = calculatePriceFor(productPrice);
if (maxPrice == null || currentProductPrice.isGreaterThan(maxPrice)) {
maxPrice = currentProductPrice;
}
if (minPrice == null || currentProductPrice.isLesserThan(minPrice)) {
minPrice = currentProductPrice;
}
}
return new CategoryPriceRange(category, minPrice, maxPrice);
}
private List<Sku> mapCoreProductToSku(List<CoreProduct> coreProducts) {
return coreProducts.stream().map(p -> p.getSku()).collect(Collectors.toList());
}
getActiveProductsFor 方法获取指定类目商品列表的代码大致如下:
class CoreProductService…
public List<CoreProduct> getActiveProductsFor(Category category) {
// 获取类目下的商品列表
List<CoreProduct> productsForCategory = coreProductRepository.getProductsFor(category);
// 只返回 is_active 的商品列表
return filterActiveProducts(productsForCategory);
}
// 根据 is_active 进行过滤
private List<CoreProduct> filterActiveProducts(List<CoreProduct> products) {
return products.stream().filter(p -> p.isActive()).collect(Collectors.toList());
}
在本例中,我们把 isActive 的检查保留在了服务中,但是把它转移到数据库查询之中也是很容易的。实际上将功能拆分为多个服务之后,很容易发现这些将逻辑下放到查询层从而提高运行效率的机会。
updateIsOnSale 功能非常直接,可以进行如下重构:
class ProductPricingService…
public void updateIsOnSaleFor(Sku sku) {
final ProductPrice productPrice = productPriceRepository.getPriceFor(sku);
productPrice.setOnSale(true);
productPriceRepository.save(productPrice);
searchProduct 方法指向新建的 coreProductRepository,用于商品搜索。
class CoreProductService…
public Sku searchProduct(String searchString) {
return coreProductRepository.searchProduct(searchString);
}
原单体应用的顶层接口是 CatalogService,这里也需要进行重构,对不同的功能调用,要委托给不同的服务——CoreProductService 和 ProductPricingService。这个过程很重要,它保障了现有的客户端和服务端之间的契约。
searchProduct 方法委托给了 CoreProductService:
class CatalogService…
public Sku searchProduct(String searchString) {
return coreProductService.searchProduct(searchString);
}
定价相关的方法则委托给了 productPricingService:
class CatalogService…
public Price getPriceFor(Sku sku) {
return productPricingService.getPriceFor(sku);
}
public CategoryPriceRange getPriceRangeFor(Category category) {
return productPricingService.getPriceRangeFor(category);
}
public void updateIsOnSaleFor(Sku sku) {
productPricingService.updateIsOnSaleFor(sku);
}
步骤 3:为身处单体服务当中的新服务创建数据表
这个步骤中,我们要把定价相关的数据拆分到一个新的数据表中——Productprices。这一步骤的最后,商品定价逻辑应该访问 ProductPrices 数据表,而不再是 Products 表。对任何 Products 数据表中关于商品核心信息的请求,都应该从商品核心逻辑层中获取。这个步骤中,除了 productPricingRepository 类之外,所有其他类,尤其是服务类的代码都不应被触及。
这个步骤中要把一个数据表一分为二,因此很重要的一项工作就是 Products 表到 ProductPrices 表的数据迁移。我的同事 Pramod Sadalage 写了一本关于数据库重构的书,如果希望认真的学习这方面的知识,这本书非常值得一读。要做个快速入门,可以看看 Pramod 和 Martin Fowler 的文章:Evolutionary Database Desgin。
在本步骤最后,可能会觉察到新服务可能会对整体系统造成一些影响,尤其是性能方面。逻辑层中的内存内数据 Join 的性能影响是显而易见的。在我们的例子中,getPriceRangeFor 方法就在商品核心信息和商品定价信息之间进行了一次连接。在业务代码中完成数据连接相对于数据库来说,始终是一种更大开销的操作,这也是数据解耦的代价之一。如果在这一阶段中的性能损失非常严重,那么把数据迁回的话,情况会变得更糟糕,更不要提将服务进行物理拆分之后了。如果性能需求(以及可能存在的受这次重构影响的其他需求)无法满足,那么很可能需要重新思考一下服务边界的问题。至少在目前阶段里,Web 应用和 iOS 还都保持良好,这是因为我们没有修改任何和客户端发生交互的部分。这一步骤的另一个功能,就是进行了一次物美价廉的测试。
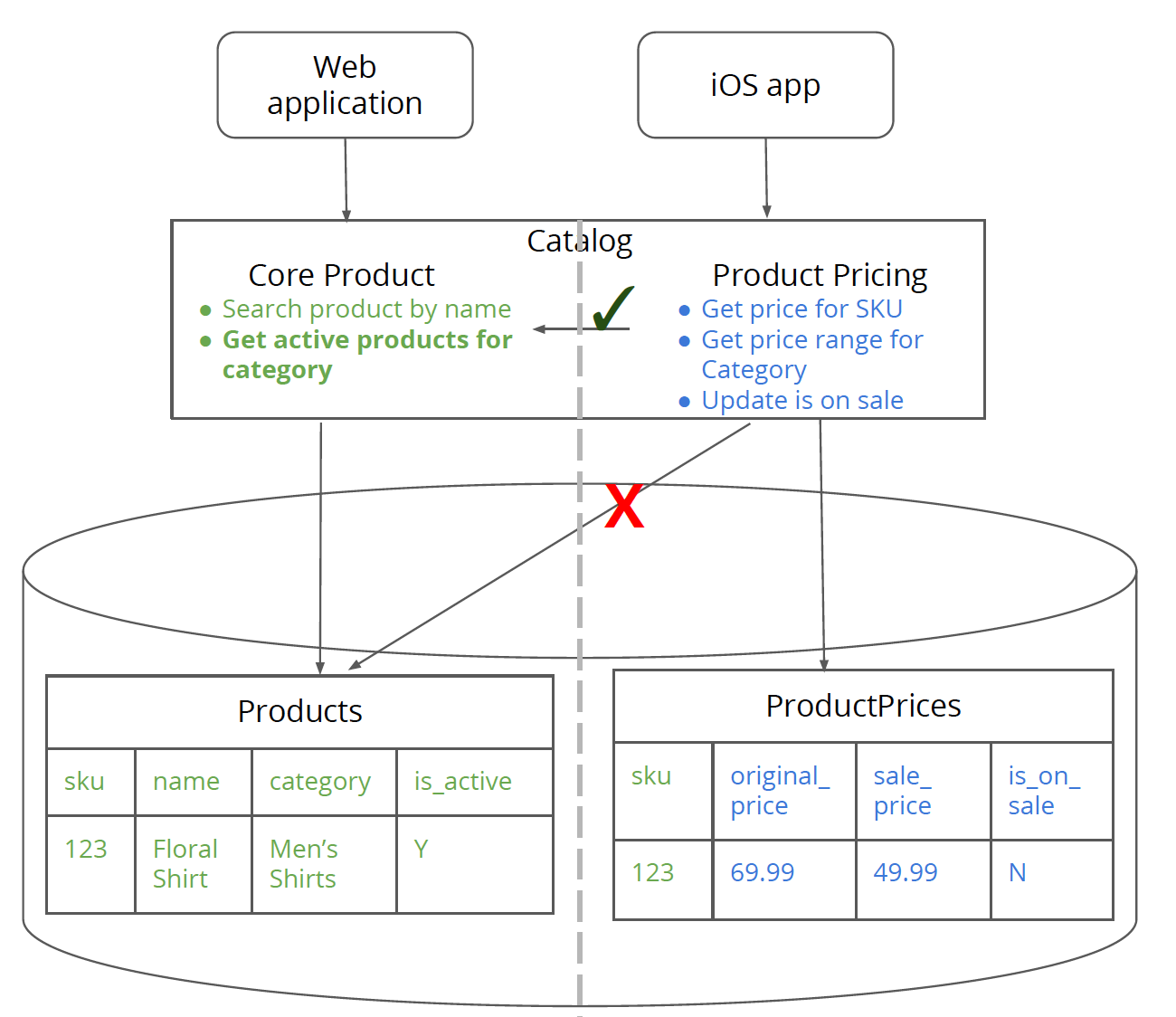
图 4:拆分成两块:商品核心的数据和逻辑,商品定价的数据和逻辑。
步骤 4:创建新的服务,并且访问单体应用的原有数据库
这个步骤中就要开始给商品定价的逻辑建立新的“物理”服务了,新的服务以 ProductPricingService 为基础,但是数据库依旧沿用单体应用所持有的 ProductPrice 数据表。注意到了这一步,ProductPricingService 调用 CoreProductService 就会变为网络调用了,这种变化不仅会对性能造成影响,还需要增加对超时等网络调用特有问题的处理。
这也是一个业务抽象验证的好机会,这里可以看到新的商品定价服务的建模到底针对的是技术方案还是业务需求。例如当业务用户在执行 updateIsOnSale 时,他的真正需要是在系统中给特定商品创建一个“促销”。下面的代码就是重构以后的 updateIsOnSaleFor。我们响应业务需求,对功能进行了改进,在参数中加入了促销价格,这在以前是没有的。这还是一个将从前流落到客户端的逻辑重新归纳到服务级别的好机会。在客户端的角度来看,这明显是一个有利的变更。
class ProductPricingService…
public void createPromotion(Promotion promotion) {
final ProductPrice productPrice = productPriceRepository.getPriceFor(promotion.getSku());
productPrice.setOnSale(true);
productPrice.setSalePrice(promotion.getPrice());
productPriceRepository.save(productPrice);
}
当然这些重构并非天马行空任意施为的,其中一个重要限制就是不能修改表结构以及表数据的语义,否则可能会破坏掉单体应用中的已有功能。服务拆分大功告成之后(步骤 9),就可以对自己的数据库以及代码为所欲为了。
你可能想要在进行客户端迁移之前进行这一变更,尤其是在大型组织机构中,要让大量不同的服务消费者在限定时间内进行迁移,这一过程需要消耗大量的时间和金钱。下一步中会详细讨论这一问题。新的定价服务可以安全的部署到生产环境中进行测试——反正没有客户端在使用这一服务。同样这里对客户端没有任何变更,例如本例中的 Web 应用和 iOS App 都没有受到任何影响。
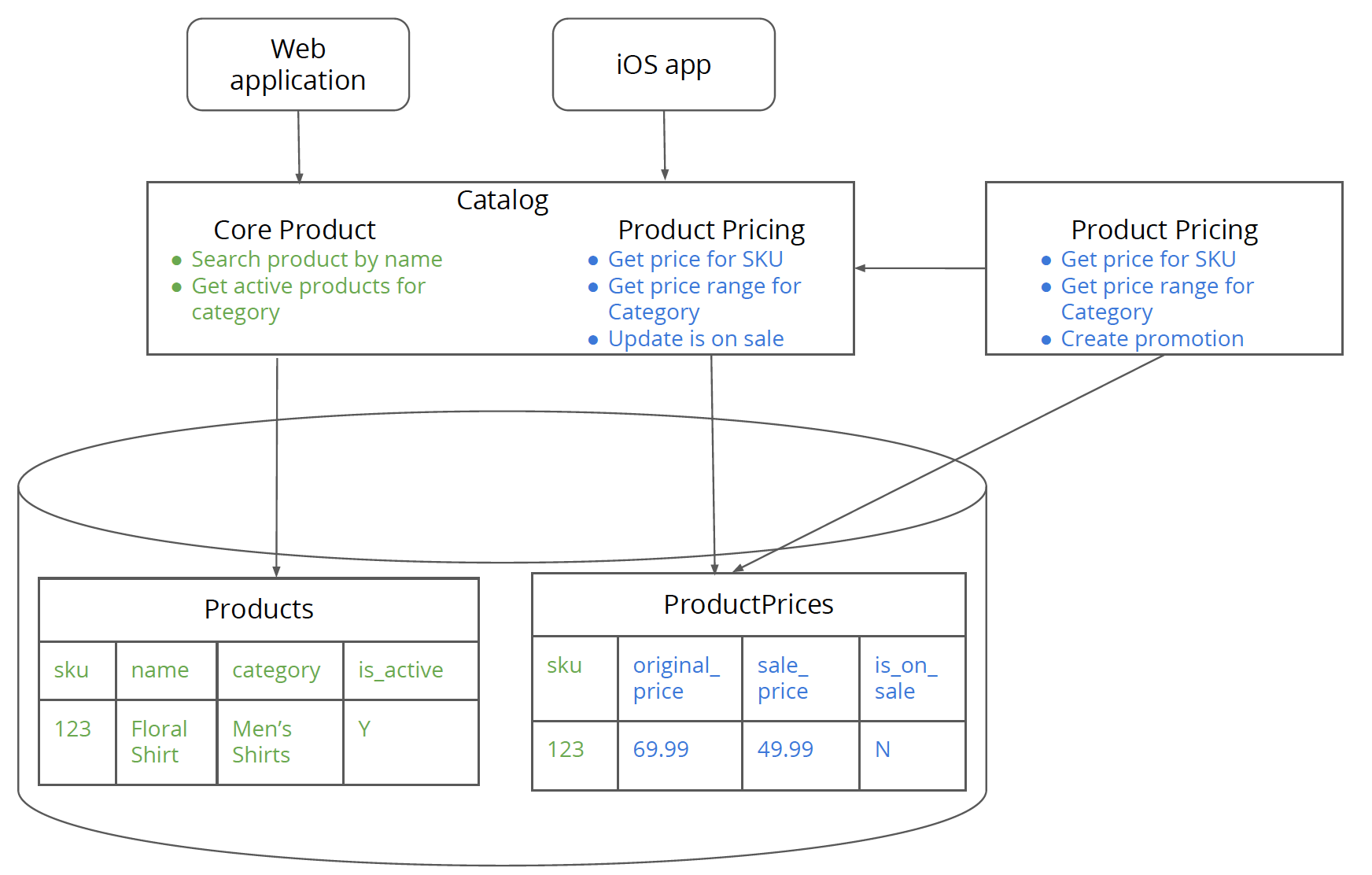
图 5:商品定价服务分拆成了新的“物理”服务,新服务在数据方面要依赖单体应用中的
ProductPrices表,而功能上则要依赖于单体应用中的核心产品功能。
步骤 5:让客户端使用新的服务
这个步骤里,单体服务的客户端中涉及商品定价的部分就需要转移到新的服务上了。这一阶段的工作有两个依赖项:
- 新旧结构中有多少接口发生了变更。
- 在组织视角,有多少客户端团队需要及时进行迁移。
这一步骤启动以后,整体架构可能会处于一个中间状态:新旧服务都有客户端在访问。这种状况实际上是比初始状态更加糟糕的。这就是前面讨论过的原子化的架构演进原则的必要性。在迁移开始之前,要获得组织的确认,所有新功能的相关客户端能够按时完成迁移。在架构处于半完成状态期间,是非常容易受到其他的所谓高优先级问题的干扰的。
好消息是,并非所有客户端都需要同时进行迁移。然而在进行下一步之前,完成所有的客户端改造是必要的。可以设置一些服务级的监控机制来监视定价相关的方法,来识别没有完成相关变更的客户端。
理论上可以在客户端完成改造之前开始一些下一步的工作,尤其是下一步中包含了创建定价数据库的操作,但是为了工作的简化,我还是建议尽量按照顺序完成步骤。
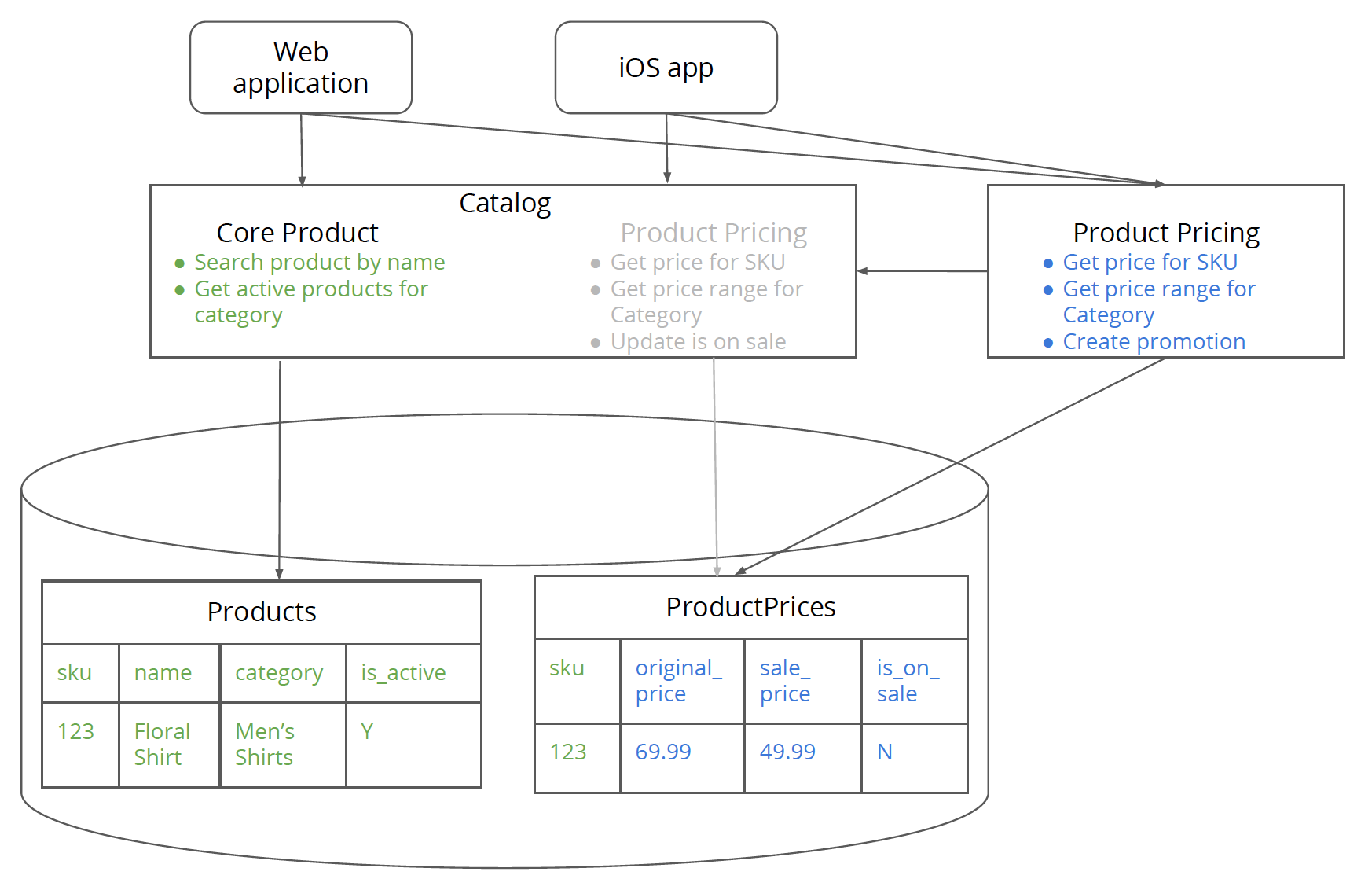
图 6:要使用定价功能的客户端已经迁移到新的定价服务。
步骤 6:为新服务创建数据库
这一步相对简单,从单体应用的数据表中进行镜像,创建新的定价数据库。这一过程中有个很大的诱惑就是:既然代码已经进行了重构,干脆也对定价数据库进行一次重构吧。但是数据结构的变化会提高后面将要进行的数据迁移过程的难度。这还意味着新的新的定价服务同时要支持两套不同的结构。我还是建议让事情简单一点:首先分离定价服务(终结所有本文中提到的步骤),然后单独对定价服务进行重构。定价数据库的隔离一旦完成,对数据库的修改就很容易了,毕竟没有客户端会直接访问数据库。
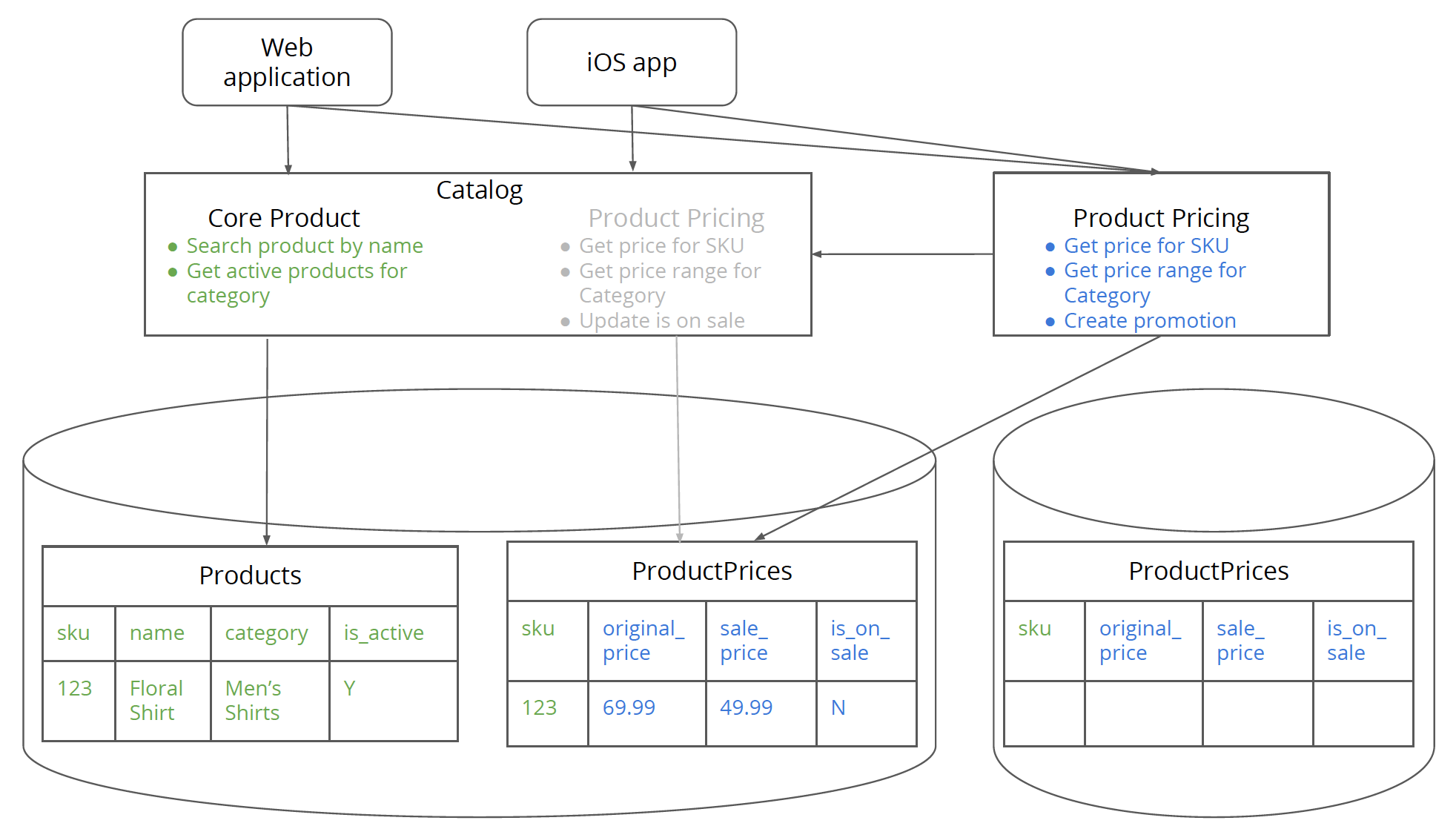
图 7:独立的定价数据库已经建立。
步骤 7:同步数据到新数据库
这一步需要从单体应用的数据库中把定价表的数据同步给新的定价数据库。如果结构没有发生变化,那么这个同步过程是非常简单明了的。基本上相当于把定价数据库设置为原有数据库的只读副本过程(仅涉及到定价相关的数据表)。这样也能保障新的定价数据库的及时性。
迁移完成后,就可以准备在下个步骤中,让独立的定价服务来访问新的定价数据库了。
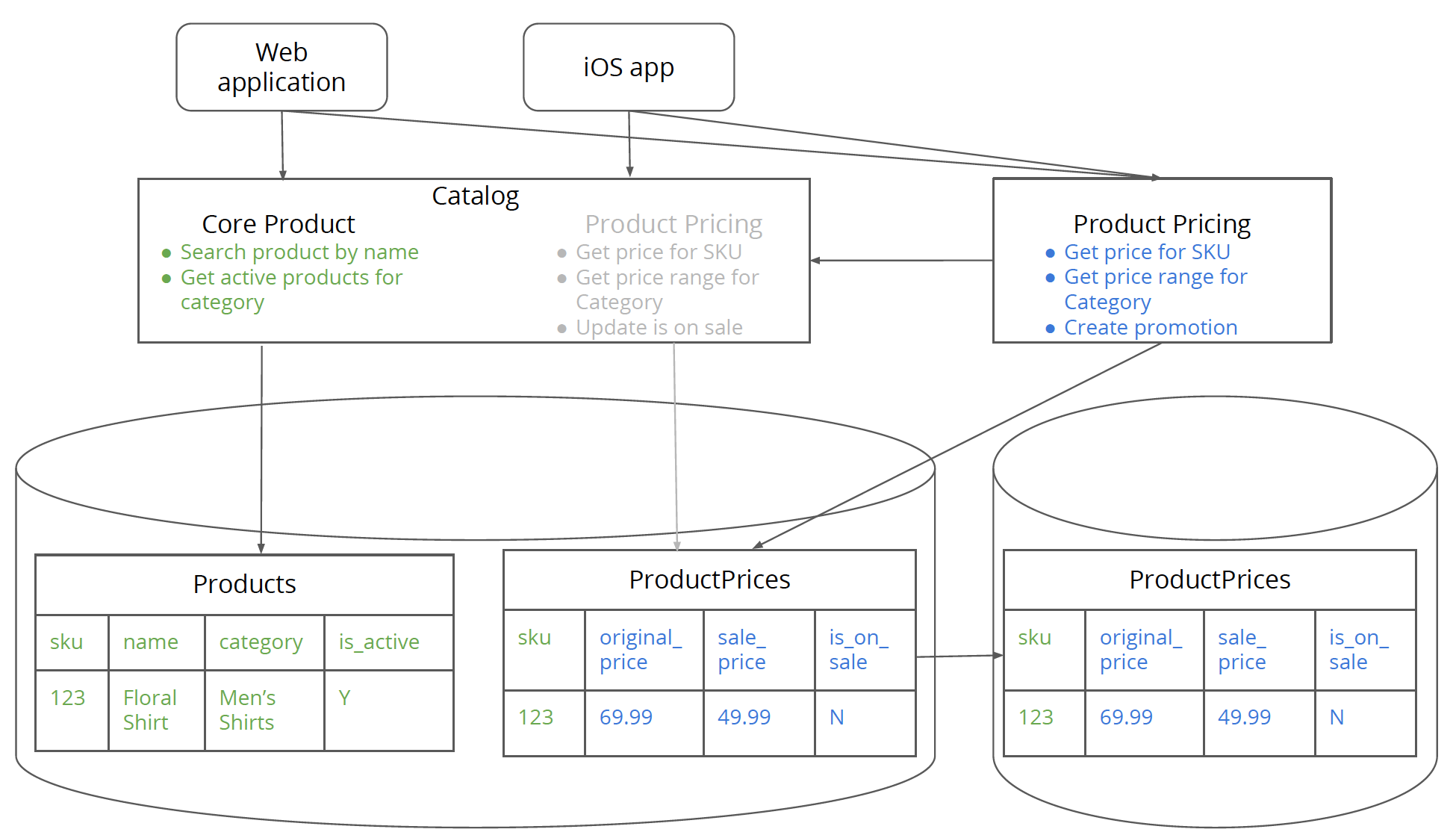
图 8:从旧数据库中同步定价数据表给新建的定价数据库。
步骤 8:让新服务使用新数据库
开始之前,必须要保证所有使用定价功能的客户端迁移到新的服务上去。如果没有,就面临着写入冲突的风险,这也是前面强调“唯一写拷贝”原则的理由。所有客户端都迁移到新的服务端之后,就需要将定价服务指向新的数据库了。简单说来就是把数据库连接进行一次切换。
这样做的一个好处就是在出现问题的时候,还有机会轻松的迁移回到原数据库。有一种常见问题就是,新数据库中缺乏一些新服务所必须的数据表或者字段。这是步骤一中的失误所产生的后果。有可能是缺少了一些必要的引用数据,比如货币代码。成功解决这些问题之后,就可以进入下一步了。
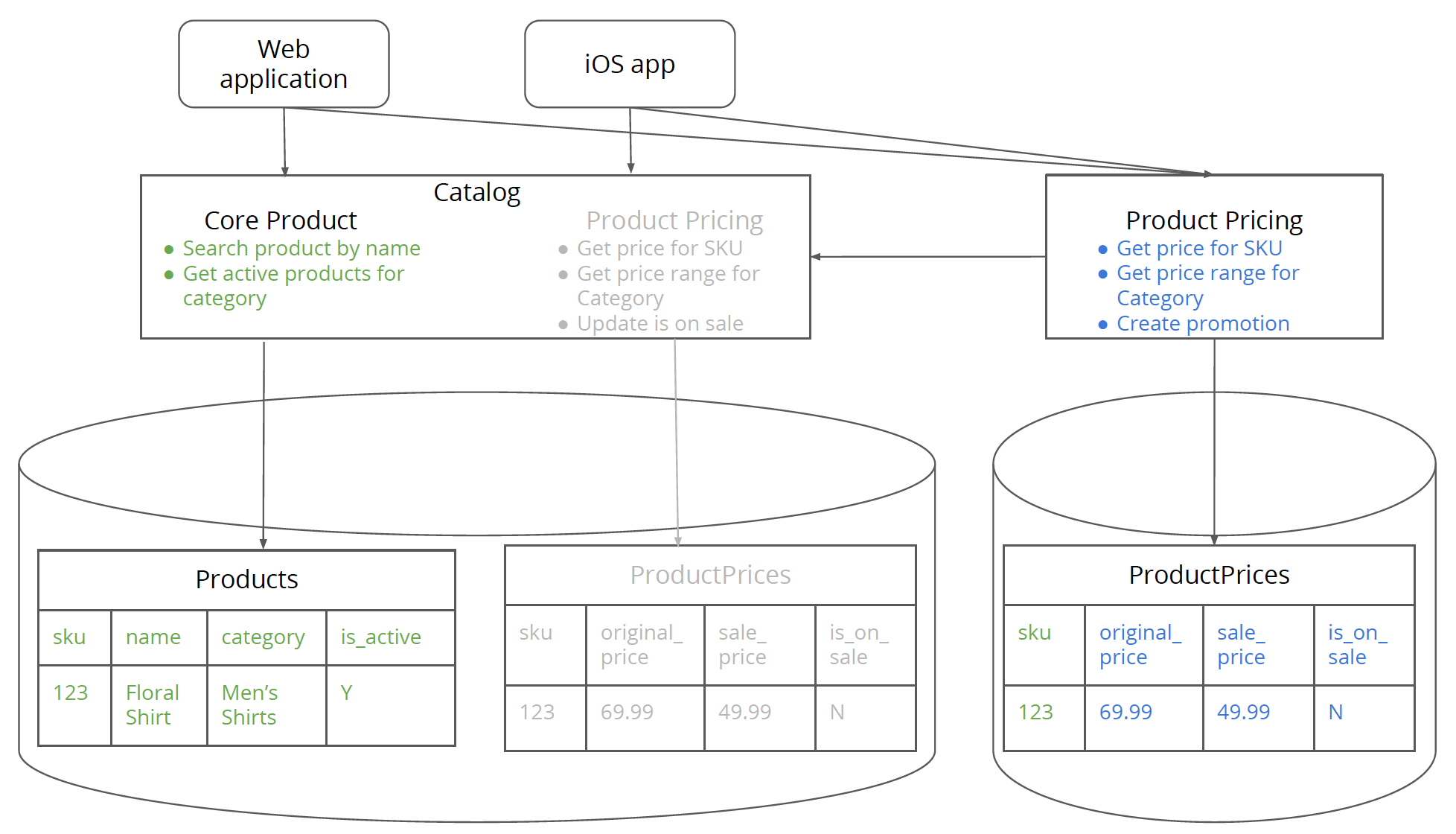
图 9:指向定价数据库的定价服务。
步骤 9:从单体应用中删除新服务相关的逻辑和数据
这里就要从原有应用中删除定价功能相关的逻辑和数据库了。很多团队会在数据库中留着旧数据,仅仅是因为担心“万一有用呢?”。进行一次全库备份可能有助于缓解这种恐惧。
现在 CatalogService 的所有功能都委托给了对 CoreProductService 服务的调用,顺理成章地,我们就可以移除这一中间层,让客户直接调用 CoreProductService 服务了。
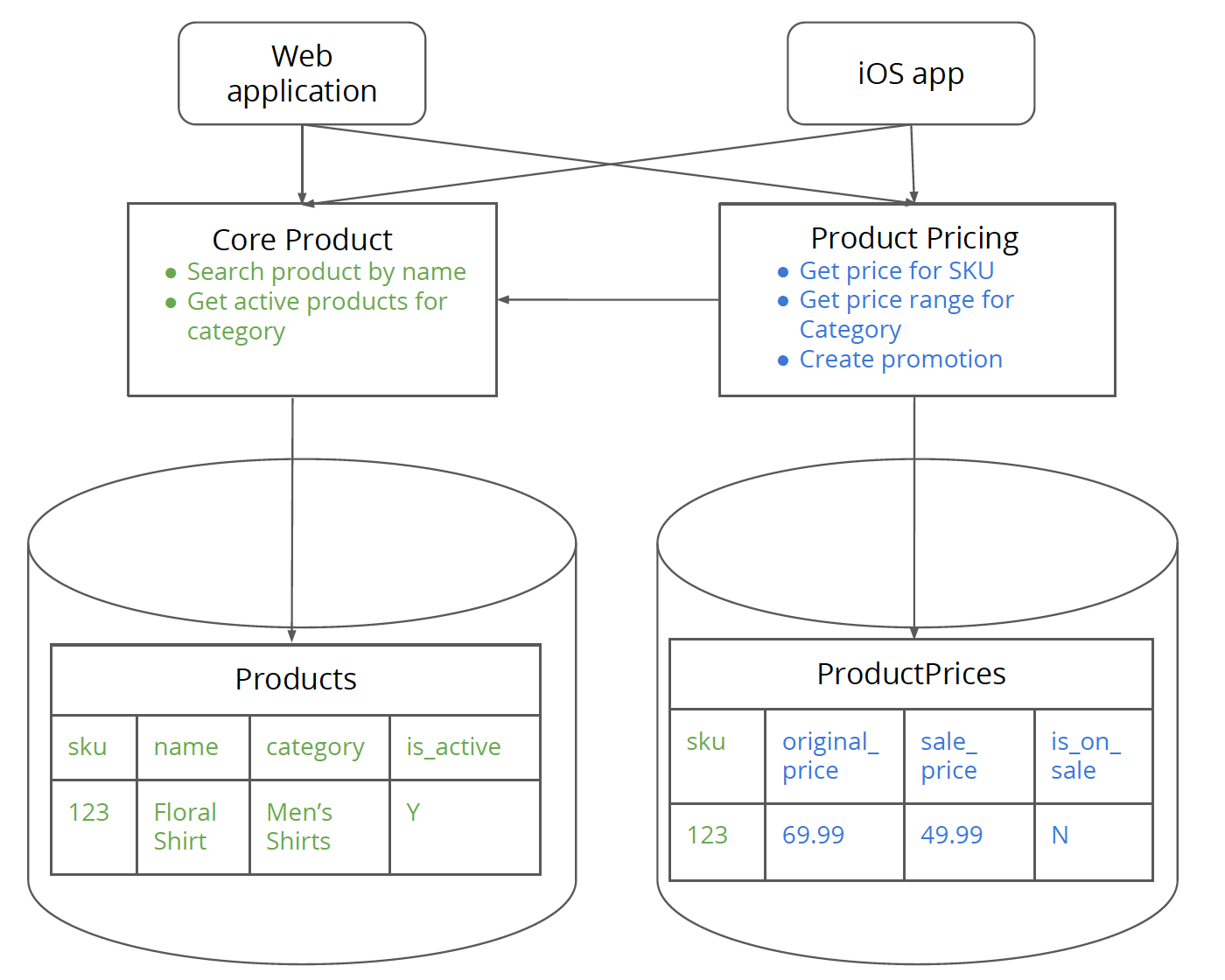
图 10:商品核心只有商品核心的相关逻辑和数据;商品定价服务持有定价的逻辑和数据,二者仅在逻辑层面进行交互。
总结
大功告成!我们成功的把一个富数据的服务从单体应用中解放了出来。
第一次进行这项工作时,会有很多痛苦,也会受到很多教训,这都会让你的下一次拆分更加顺利。初次拆分过程中,不管面对多大诱惑,都最好不要尝试合并这些步骤。一次只进行一步,让整个工作流程更少悬念,更多的安全感和可预测性。在成功掌握这一模式之后,就可以根据自身所学对这些步骤进行优化了。
祝你好运!