Istio:503、UC 和 TCP
原文:Istio: 503’s with UC’s and TCP Fun Times
最近 AutoTrader 在调试一个有些复杂的问题,这一过程得到了 Istio 团队的很多帮助。这个问题现在已经基本得到了解决,这一过程中采取的一些措施可能对其他用户有所启发,因此有了本文。
问题
我们注意到有些请求在第一次尝试的时候会失败,Istio 会自动进行重试,然后就成功了。在 Jaeger 中观察可以看到:第一个请求是 503 状态,response_flags 为 UC。

如果你在关注或者正在使用 Istio,你可能会看到很多千奇百怪的 503。目前 503 的主要问题就是,它太模糊了。
看看这个简单的例子:

基本上,应用 2 的 Envoy 和应用通信过程中的任何问题都会被包裹成 503,发送回上游,然后上游就会进行重试。
不管怎样,有了 Istio,重试并不是世界末日。Istio 检测到故障后进行重试,然后给上游返回了成功信息。然而值得注意的是,故障总会发生,我们应该面向故障进行应用的构建。我们的应用跨越多个 AZ,出现这种奇怪的问题,会有很多可能的错误源头。
我们观察到,大概 0.012% 的请求发生了这种问题。我们的应用是一种微服务架构,这一种故障和 5 个应用相关,这样会看到 0.08% 的聚合请求失败率,(稳定的故障率)表明,这并非是偶然情况。
当你开始考虑这一故障时,会注意到 Sidecar 模型增加了应用通信过程的复杂度,这就是网格的代价之一。
回忆一下没有服务网格的世界,consumer-gateway 管理一个通往 sauron-seo-app 的连接池。然而有了服务网格,我们其实有了三个各行其是的连接池,各有各的配置:

consumer-gateway到source-envoy:Java 代码。source envoy到destination envoy:DestinationRule。destination envoy到sauron-seo-app:在 Envoy 中进行配置,Istio 对其配置并无掌控。
这中间有很多出问题的机会,要查找根本原因,也有很大的排查范围。因此我们对真实场景中这一问题的应对方法进行回顾。
指标
Istio
Istio 搜集了很多的指标,能帮我们凸显问题。Istio 提供的这种水平的可观测性很有趣,能能够凸显你之前发现的问题。这很直白,所以打开 Prometheus 并输入:
sort_desc(sum(changes(istio_requests_total{response_flags="UC", response_code="503", reporter="destination"}[24h])) by (source_app, destination_app, reporter) >0)
这段指标的含义是:最近 24 小时内,状态为 503 并且被标记为 UC(上游连接问题),使用 source_app、 destination_app 以及 reporter 进行汇总。
注意:上图中,reporter=source 就是来自于源 Envoy,而 reporter=destination 就是目标 Envoy。
所以看看我得出的结果,{destination_app="sauron-seo-app",reporter="destination",source_app="consumer-gateway"} 58,这代表过去 24 小时里,从 consumer-gateway 到 sauron-seo-app 的请求中有 58 个出了问题,得到了 503UC 的结果,这一情况是由 sauron-seo-app 的 Envoy 汇报而来。
我们知道了,我们在目标一端发生了问题,这也跟前面的跟踪过程中得到的结论是一致的:源服务尝试了一个不同的目标并获得成功。我们来检查一下 Envoy 发生了什么事。
Envoy
我们要做的下一件事就是启用一些指标,帮助我们对 Envoy 进行排查。缺省情况下 istio-proxy 只提供一些核心的 Envoy 指标。我们需要更多信息。在 Deployment 里加入下列注解:
sidecar.istio.io/statsInclusionPrefixes: cluster.outbound,listener,cluster,cluster_manager,listener_manager,http_mixer_filter,tcp_mixer_filter,server,cluster.xds-grpc
注意:这个指标的数据量较大,缺省是关闭的。我只会在进行排错的时候才启用这些指标,并且在完成工作后就会关闭它们。
完成这一操作后,就会看到一些新指标,例如 envoy_cluster_upstream_cx_destroy_local_with_active_rq 和 envoy_cluster_upstream_cx_destroy_remote_with_active_rq。这些指标来自 Envoy 的视角,因此它的本地和远程是这样的:

envoy_cluster_upstream_cx_destroy_local_with_active_rq
本地销毁的产生一个以上活动请求的链接数量。
听起来很恐怖吧?没人希望活动请求被杀掉,我们的目标 Envoy 说,有大量的远程销毁,而我们的源 Envoy 有大量的本地销毁。
这看起来云山雾罩,所以我觉得最简单的排查方法就是把他们列在一起。这样就会看到 local 指标在源 Envoy 中出现,而目标 Envoy 中报告了 remote 指标:
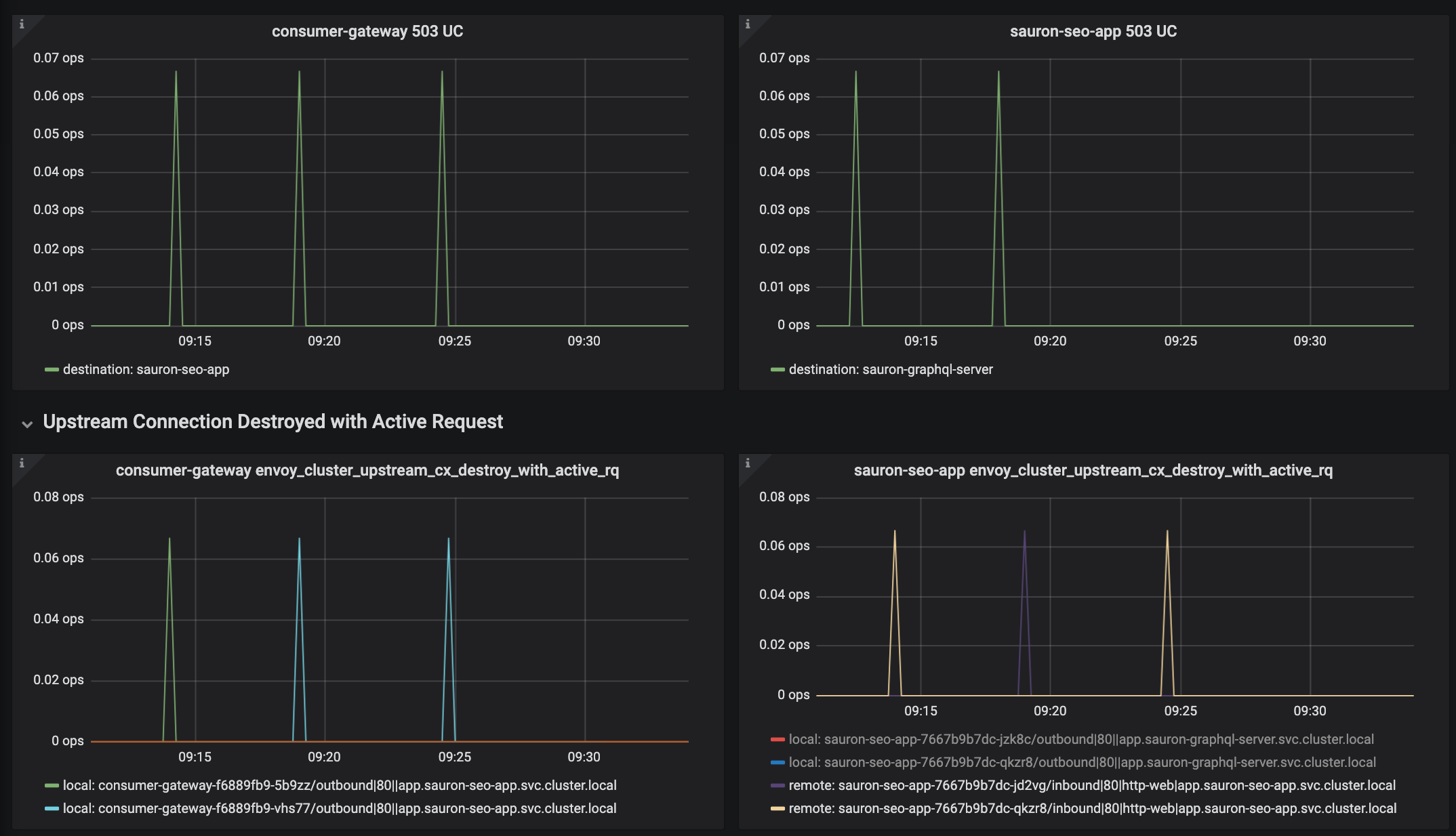
上图说明 sauron-seo-app 的 Envoy 和应用之间的连接关闭了。看起来是 sauron-seo-app 关闭了(远程关闭)。然后 consumer-gateway Envoy 也随即关闭了连接。这就能够解释 consumer-gateway 在 HTTP 1.1 连接中(Envoy 之间的通信)收到的 5xx 响应了。这个连接无法继续发送数据,除了关闭,别无他法(本地关闭)。
注意:这不是 http2.0 的情景,看起来 Istio 1.2 会有能力把 Envoy 之间的连接池切换为 http2.0。
这样我们就决定,要进一步对 sauron-seo-app 进行观察。
istio-proxy debug 日志
istio-proxy 能够在运行时修改日志级别,对排除这类问题很有帮助。所以我们把这些日志设置为 debug 级别:
kubectl exec -n sauron-seo-app sauron-seo-app-7667b9b7dc-jd3vg -c istio-proxy -- curl -XPOST -s -o /dev/null http://localhost:15000/logging?level=debug
看看是否能有所斩获。
修改日志级别后,可以用 tail 来查看一下日志(可能有非常多的输出)。会看到 503 的相关内容:
[2019-05-30 08:24:09.206][34][debug][router] [external/envoy/source/common/router/router.cc:644] [C77][S184434754633764276] upstream reset: reset reason connection termination
[2019-05-30 08:24:09.206][34][debug][filter] [src/envoy/http/mixer/filter.cc:133] Called Mixer::Filter : encodeHeaders 2
[2019-05-30 08:24:09.206][34][debug][http] [external/envoy/source/common/http/conn_manager_impl.cc:1305] [C77][S184434754633764276] encoding headers via codec (end_stream=false):
':status', '503'
'content-length', '95'
'content-type', 'text/plain'
'date', 'Thu, 30 May 2019 08:24:08 GMT'
'server', 'istio-envoy'
[2019-05-30 08:24:09.208][34][debug][connection] [external/envoy/source/common/network/connection_impl.cc:502] [C77] remote close
[2019-05-30 08:24:09.208][34][debug][connection] [external/envoy/source/common/network/connection_impl.cc:183] [C77] closing socket: 0
这里我们看到了 503 出现在连接 [C77] 上。如果我们后退一下,会看到 [C77] 连接上还有一段:upstream reset: reset reason connection termination。 istio-proxy 告诉我们,上游复位了 77 号连接(这里的上游指的就是应用程序)。这进一步证实了,Envoy 认为 sauron-seo-app 关闭了连接。
抓包
目前为止,我们用了很多的 Istio 和 Envoy 提供的功能,我们大概知道,很可能是目标应用断掉了连接。是时候开始抓包来进一步研究了。
为了在 Kubernetes 上完成这个工作。我们使用了一个叫做 ksniff,我得说,这个工具太棒了。因为我们运行的是非特权容器,因此无法在应用中进行 tcpdump。ksniff 可以:
- 检查你的目标应用运行在哪个节点上。
- 部署一个和这个节点有亲和的 Pod,绑定到 Host network。
- 从特权应用对流量进行 TCP Dump,并把流量发送回你笔记本上的 Wireshark。
TCP Dump 很吵,所以我们会做一下过滤:
- 我们关注的是 TCP 连接相关的事件,所以只需要看
SYN、FIN和RST。 我们要观察的是本地 Envoy 和应用之间的流量,我们只想关注
localhost,所以-i lo就可以只查看 loopback 适配器了。kubectl sniff $pod -p -n $namespace -c istio-proxy -f ‘tcp[tcpflags] & (tcp-syn|tcp-fin|tcp-rst) != 0’ -i lo
我们很快就能看到 RST,表明的确是我们的应用关闭了连接。

这就很清楚了,Envoy 应该能够处理上游的关闭连接。然而在极少数情况(0.003%)下,我们发现 Envoy 尝试向被应用关闭的连接中发送数据。Istio 团队还在尝试理解这种情况发生的原因(似乎是在服务端发送 RST 和 Envoy 复用连接池中的连接的过程中发生的争用),并能够更好的处理这种场景(1.1.8 之后)。
Istio 成员发现,在连接开始(SYN)和复位(RST)之间,总有五秒左右的间隔。
我们的服务器是 nodejs,Google 搜索发现了 Nodejs 文档中的一段内容:
以毫秒为单位的超时时间,缺省值 5000(5秒):服务器在处理完最后一个响应之后,等待新数据进入的时间,如果超过这一时间都未进行活动,就会销毁该 Socket。
由上述文档看来,虽然 Envoy 为应用创建了连接池,但是应用会在发呆 5 秒钟之后销毁 Socket。这个超时太短了。
TCP Socket 超时
我们做了一番挖掘,我们发现不止在 Nodejs 中有这种情况,Python 应用、Java/Tomecat 都有这种问题。缺省设置如下:
- nodejs:5 秒
- python:10 秒
- tomcat:20 秒
所以 Socket 超时越短,RST 就会越多,也就会有越多的 503 问题。
Istio 团队正在积极的寻求改进方法,我们发现可以简单的设置一个更高的 Socket 超时时间来解决这一问题。
Nodejs
const server = app.listen(port, '0.0.0.0', () => {
logger.info(`App is now running on http://localhost:${port}`)
})
server.keepAliveTimeout = 1000 * (60 * 6) // 6 minutes
Python
global_config = {
'server.socket_timeout': 6 * 60,
}
cherrypy.config.update(global_config)
Java-Spring
server:
connect-timeout: 360000
下图就是我们修复问题的结果:
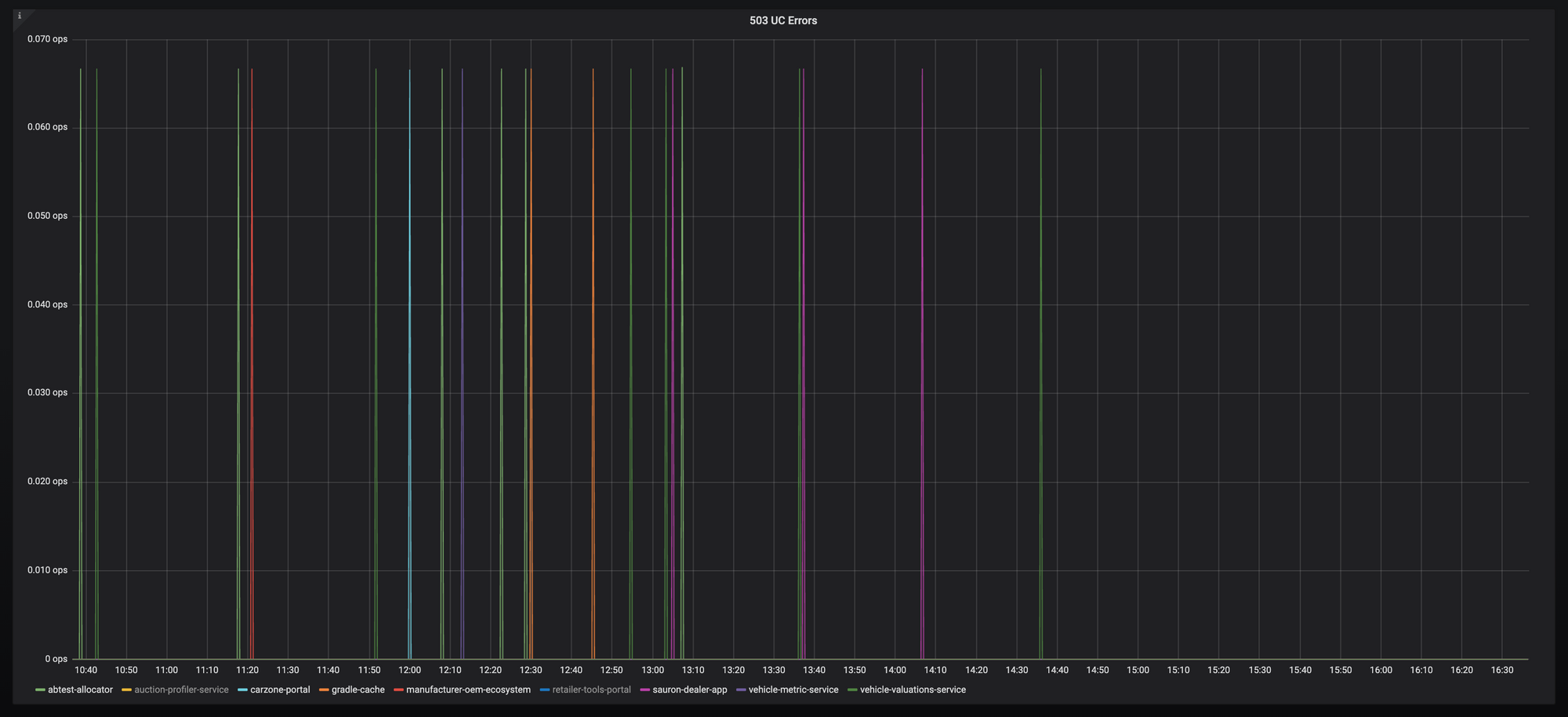
我知道 Istio 团队正在努力改进这方面的 UX 问题,尽可能高效的处理这类场景,让 Istio 为更多用户提供开箱可用的高性能表现。所以我很相信他会越来越好。
感谢 Chris McKean 和 Istio 社区的朋友们,他们在没有经历这种问题的情况下,依然提供了无私的帮助。希望这个排查过程能够对读者的工作有所助益。
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。