Istio 和 Linkerd 的性能测试分析
原文:Performance Benchmark Analysis of Istio and Linkerd
作者:Thilo Fromm
动机
过去几年里,服务网格在 Kubernetes 生态中迅速成长。Service Mesh 的价值难以抗拒,然而对摩拳擦掌的用户来说,另一个基础问题就是:成本怎样?
成本有很多种,可不仅仅是学习新技术时的投入。在这一篇报告中,我们选择了一个易于量化的方面:在一定规模的服务中的资源消耗和性能影响。要进行这个测量,我们设计一系列测试场景,针对候选产品进行测试。我们的的候选包括 Istio(来自 Google 和 IBM 的 Istio 以及 Linkerd(CNCF 项目)。
Buoyant 是 Linkerd 的首创者,他们和我们取得联系,目的是获得一个 Istio 和 Linkerd 的客观评判。这给我们一个深入服务网格技术的机会,欣然从命。
Kinvolk 目前有客户正在尝试 Istio。我们的使命是在云原生世界中促进开源技术的发展,这也是我们呈现这一对比报告的根本原因。
下面使用的测试方案也已经开放给开源社区,地址是 https://github.com/kinvolk/service-mesh-benchmark。
目标
研究过程中我们有三个目标:
提供一个可重现的测试框架,任何人都可以下载和使用。
识别最能反应服务网格运行成本的场景和指标。
根据业界在性能测试方面的最佳实践,例如控制编译来源,处理 Coordinated Omission(CO),来对流行服务网格进行评估。
场景
我们的目标是在常规大负载集群的操作环境下,理解服务网格的性能表现。这意味着在产生压力的时候,集群应用还有能力在已定时间范围内给出响应。在系统受到压力的时候,用户访问该集群所服务的页面,还能够在一个可忍受的范围内提供服务。在真实世界中,延迟增大到一定程度之后,就会采取措施进行扩容了。
在本文的测试中,测试负载(每秒 HTTP 请求)的水平是这样设置的——在给应用和服务网格施加压力的时候,运行其上的流量还在一个可控范围之内。
指标
RPS、用户体验和 CO
测试中使用一个恒定的请求速率(RPS)发送 hTTP 请求,我们对响应延迟进行测量,来确定服务网格的总体性能。同样的 RPS 也会施加到一个无服务网格的集群上,以此结果来描述集群和应用的性能基线。
我们的测试过程很注重 CO,在以 UX 为中心的视角下的一个重要因素。负载生成器只会在前一个请求完成之后才发起新请求,而不是为了满足 RPS 要求,不顾之前的请求直接按照时间点发起心情求。
比如说如果我们要做一个 10 RPS 的延迟测试,我们每隔 100 毫秒就发出一个新请求,也就是一个 10 Hz 的速率。但是如果负载生成器在等待一个耗时超出 100 毫秒的请求的结束的话,那么这个 RPS 最多只能到 9。单一请求造成了高延迟,后续的请求也会受到拖累——处理的并不慢,只是开始得晚了。这种行为有两个缺点:第一个就是刚提到的,单一的高延迟请求造成后续请求的延迟;第二就是请求的发生过程被暂停,不符合 RPS 要求。在真实情况下,高延迟问题很可能因为用户蜂拥而至,产生大量积压。
我们使用 wrk2 来生成负载并在客户端测量延迟。wrk2(Gil Tene)是流行的 http 压测工具 wrk(Will Glozer)的 Fork。wrk2 提供了 RPS 参数,可以用指定速率来生成负载,它通过在发起请求的时间点上测试延迟的方式来消除 CO 问题,还会尝试在请求迟发的情况下以双倍速率生成请求的方式来追赶进度。wrk2 还包含了 Gil Tene 的 HDR 直方图功能,提供了无损精确性的记录。越长的执行时间会有越高的精确度,这样后几个百分位的数据精度更高,也是我们更感兴趣的区域。
为了完成这个测试,我们对 wrk2 的功能做了扩展,加入了多服务器地址和多 HTTP 资源路径的支持。我们不想将这个功能独立 Fork 出来,而是会和上游合作加入我们的变更。
性能
为了评估性能,我们可以研究一下延迟的分布(直方图),尤其是尾部的最后几个百分位的延迟。这反映了我们本次测试在 UE 上的焦点:一个典型的页面或者服务,需要不止一个请求来完成动作。如果一个请求延迟了,整个动作都会变慢。单一请求的 p99 在更复杂的操作中会有很大影响,例如浏览器访问一个页面,获取页面中的资源并进行顺序渲染——这就是我们看重 p99 的原因。
资源消耗
使用服务网格会让集群消耗更多资源,和业务逻辑发生争用。为了更好地理解这一效果,我们同时衡量了服务网格控制平面和应用 Sidecar 中的 CPU 和内存消耗。在测试期间,会用一个较高频率在容器级别收集 CPU 使用率和内存用量,每次运行中会选择组件的最大资源消耗,得出所有运行中的中位数并用于出具结果。
我们注意到,内存消耗在测试结束时达到高峰。这个情况是合理的,根据上面的讨论,wrk2 用固定频率发起请求,当延迟超过一个阈值时,负载就会开始堆积,所以内存一旦分配就一直要到测试结束才会释放。CPU 使用率也会全程持续走高。
测试环境
集群
我们使用了自动部署的测试集群,方便测试过程的启动和结束,也更加容易进行统计,生成可靠的数据。
在这个服务网格性能测试过程中,我们使用了一个 5 节点的集群,每个节点使用 24核/48线程的 AMD EPYC CPU,主频为 2.4GHz,64G 内存。我们的工具可以使用可配置的节点数量,可以用不同的配置重新运行。
负载的生成和延迟的测量都在集群内完成。为了消除噪音和 Ingress Gateway 的数据污染,我们把测试聚焦在应用之间的服务网格。负载生成器作为一个 Pod 部署在集群中,我们保留一个节点,用于负载生成和指标测量,在其它四个节点运行一定数量的应用实例。为了合理的统计分布,我们每次运行都会随机选择一个节点来运行负载生成器。
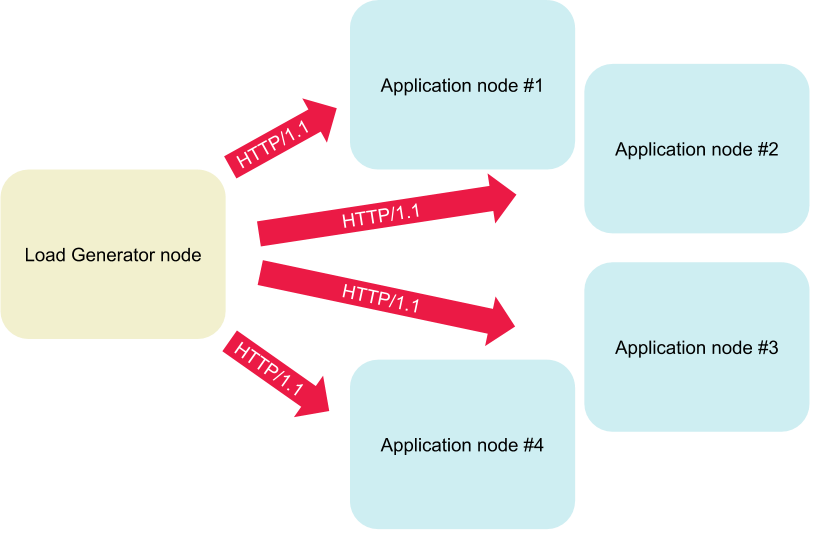
每次运行之前,会随机选择一个节点专门用于生成负载。其它节点运行应用负责承担负载。
为了完成这次测试,我们选择 Packet 作为我们的 IaaS 供应商,工作节点我们选择了 c2.medium。Packet 提供了裸金属服务器,这样就让我们避免了虚拟化环境中常见的干扰问题。
应用
根据前面的讨论,我们选择 wrk2 生成负载,并对这一工具进行了定制,可以同时访问多个 HTTP 端点。
我们用来运行测试的目标应用是 Linkerd 的演示应用 Emojivoto,这个应用自身跟 Linkerd/服务网格 的功能并无相关,Emojivoto 使用一个名为 web-svc(type: load-balancer)的 HTTP 微服务作为前端。web-svc 使用 gRPC 和 emoji-svc(提供表情符) 以及 voting-svc(提供可控的投票)后端进行通信。这个应用简单清晰,包含了测试所需的云原生应用的所有要素,因此我们选择它作为测试应用。
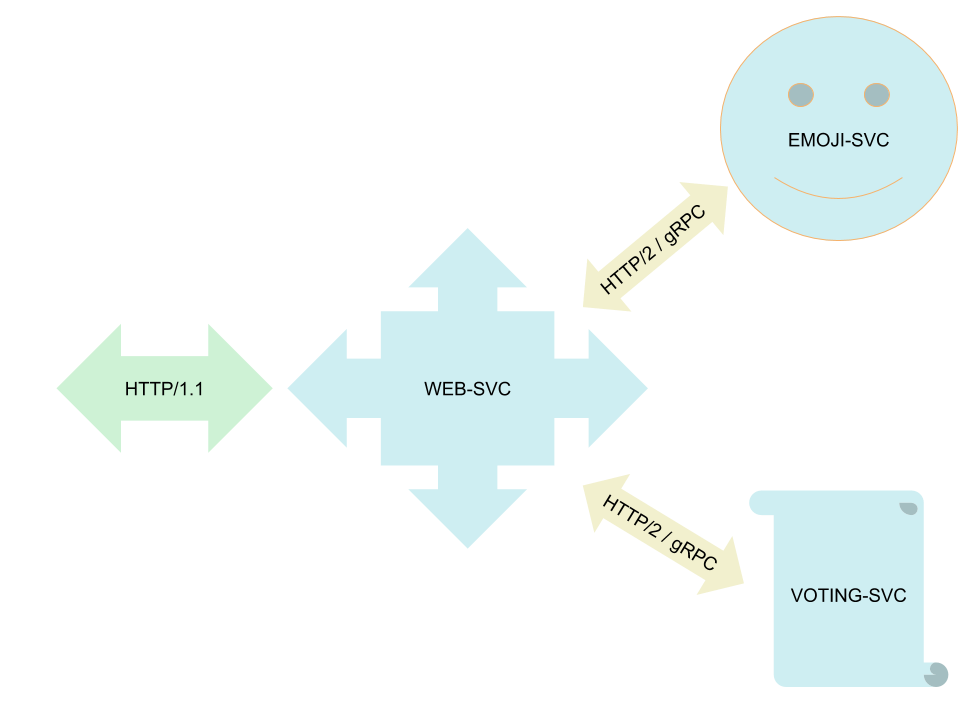
Emojivoto 应用包含了三个微服务。
然而只用一个应用进行服务网格测试,是很不现实的,真实世界中的服务网格,应该有复杂的多应用的部署。为了在保持简单的情况下更加仿真,我们用可部署的份数来部署 Emojivoto 应用,每个应用的名字中都加入序号。例如 web-svc-1、emoji-svc-1、voting-svc-1 以及 web-svc-2、emoji-svc-2、voting-svc-2。我们的负载均衡会将请求分发给所有这些 App,观察固定的 RPS。
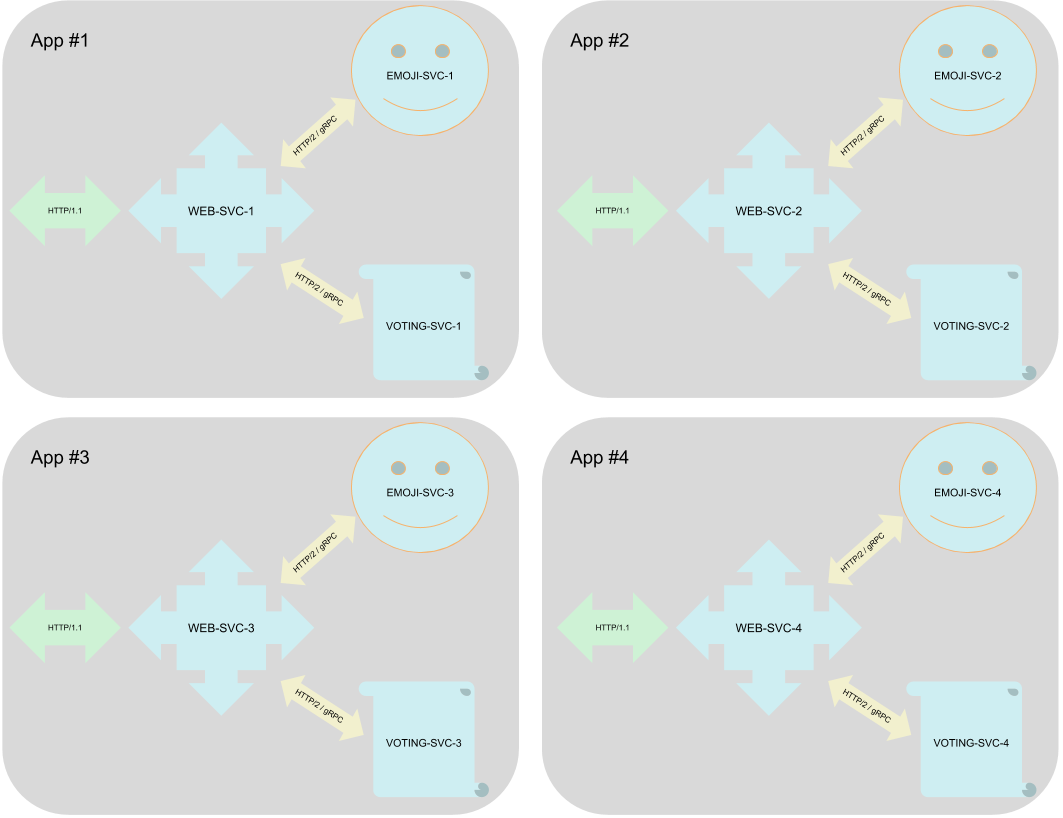
循环利用 YAML,并在名字中加入序号,部署多套应用。
运行测试和统计的稳健性
因为我们使用的是 Packet 提供的公共数据中心来运行我们的测试,所以也不能选择特定的服务器来进行部署。服务器的年龄和他的部件(内存、CPU 等),数据中心中的相对位置(同一个机架、房间、安全区),以及节点之间的物理连接,这些情况都会对测试的原始数据产生影响。其它服务器和我们的测试无关,但是在同一个数据中心内,共享同样的物理网络资源,也是可能对测试造成干扰的,最终会产生不可靠的测试数据。我们的每个数据点都有足够的统计分布样本,这样在进行对比的时候就能消除同一网络内外部因素造成的影响——例如 Istio 和 Linkerd 的延迟以及资源消耗方面的对比。我们还使用了不同数据中心的多个集群进行了测试,这也让我们对测试数据的可靠性信心大增。
为了得到足够的统计分布,我们会每个测试都会运行两次,以得出平均值和标准差,我们在两个集群上同时独立部署,防止遭遇低档硬件或者故障网络,或有服务器被放置在数据中心的角落。
典型的性能测试一般有几个步骤,这些步骤会在两个集群上同时运行,来消除上面提到的隐患。
测试之前,重启所有工作节点。
在两个集群的
istio-stock、istio-tuned、linkerd、bare命名空间中,分别:- 安装服务网格(当然,不包含
bare)。 - 部署 emojivoto 应用。
- 部署负载生成器 Job。
- 等 Job 结束,每 30 秒拉取一次资源消耗数据。
- 拉取测试结果日志,其中包含了延迟指标。
- 删除敷在生成 Job 以及 emojivoto。
- 删除服务网格。
- 回到第一步,测试下一个服务网格(顺序为:Linkerd->Istio->Bare)。
- 在所有的 4 个测试结束之后,再运行第二次,以满足统计需要。
- 安装服务网格(当然,不包含
重现性
w我们使用的是 Kinvolk 最近发布的 Kubernetes 发行版:Lokomotive。用于集群部署以及用于测试的代码都是开源的,保存在 Github 上。允许重新进行测试,也希望能够从其它用户那里得到改进。
测试的运行和观测
我们在 bare(无服务网格)、istio-stock(无微调)、istio-tuned 以及 Linkerd 上,用 500 的 RPS 运行 30 分钟。在两个集群上各运行两次,每种数据就有了 4 个样本。测试集群分布在两个不同地理区域的不同的数据中心,一个是 Packet 的 Sunnyvale 数据中心,另一个是纽约的 Parsippany 数据中心。
服务网格的版本
Istio:stock 和 tuned
我们用 Istio 1.1.6 运行这一测试,stock 运行的是根据安装文档进行部署的版本,tuned 版本则移除了内存限制,禁用了部分 Istio 组件,执行了不少推荐的微调。尤其是我们禁用了 Mixer、Policy、Tracing、Gateways 以及 Prometheus。
Linkerd
我们使用的是 Linkerd 的 Linkerd2-edge-19.5.2。我们使用的是 Linkerd 的标准配置,没有进行任何调整。
测试服务网格的上限
在使用稳定吞吐量开始长期运行之前,我们用一个较短的测试来确定服务网格吞吐量和延迟的范围。我们的目标是找到一个负载点,在这个点上,网格还能够用可接受的性能来处理流量。
为了我们的测试,我们运行了 30 个 Emojivoto 应用,也就是 90 个微服务,平均下来每个节点有 7.5 个应用 22 个微服务。我们用多个 RPS 各运行 10 分钟,来确定前面所说的负载点。
测试运行时间
我们最有兴趣的是尾部的百分位,因此测试的运行时间就很有影响了。越长的运行时间,在 99.9999 百分位和 100 百分位上的延迟就会越高。为了模拟用户涌入造成的高峰、以及新计算资源加入后的恢复,我们决定了 30 分钟的运行时间。注意,我们认为在多数环境里,尤其是自动伸缩的环境中,新资源的加入周期应该远低于 30 分钟;我们还认为,一个健壮的应用环境中,30 分钟足以应对扩容方面的意外。
第一次测试:500 RPS,30 分钟
这次测试运行超过 30 分钟,500 RPS。
延迟分布

我们在对数中观察到裸金属案例运行中,出现了很大的错误——可能是 Packet 的问题。这个情况在 99.9 和 99.999 上尤其明显,然而其他的数据点还是证明了整体趋势。我们看到 Linkerd 在这方面是胜出的,Istio 的缺省配置和微调配置相差不大,接下来看看资源消耗。
内存和 CPU


我们在 4 个独立测试运行的过程中,测量了内存分配和 CPU 使用率,在这 4 个样本中,使用了中位数以及最高最低值。Linkerd 控制平面内存消耗的异常点是由 linkerd-prometheus 容器造成的,它消耗了 Linkerd 平面其他组件内存的两倍。
而 Istio 中,我们看到了几次控制平面容器(Pilot 及其代理)消失的情况。我们不明白其中的原因,也没有深究,也没有把消失的容器计入结果。
第二次测试:600 RPS,30 分钟
这次测试运行超过 30 分钟,600 RPS。
延迟分布

我们再次观测到了裸金属测试中的抖动;然而其影响比 500 RPS 的时候更小。我们逼近了 Linkerd 的可接受响应时间的上限,在 100 百分位上的是 3 秒钟的延迟。
Istio 轻松的把延迟时间推到了分钟级(别忘了 Y 轴是对数),我们还看到了大量的 Socket/HTTP 错误,占了大概 1%-5.2%,中位数在 3.6%。我们要指出,Istio 的 RPS 承受范围在 565 和 571 之间,中位数是 568。Istio 在本次测试中没能达到 600 RPS。


上图的对比不太公平——我们看到的是 Linkerd 在 600 RPS 时候的表现,而 Istio 的是 570 RPS——但我们还是看得出,Istio 这里的资源需求。我们再次观察到 Istio 容器消失的情况,同样做了忽略处理。
结论
与裸金属相比,在常规条件下,Linkerd 和 Istio 的开销都算是可以接受的。当进入高负载状态时,相对于 Istio,Linkerd 能够提供更高的 RPS,并且使用更少的资源。
下一步
基于上面测试的观察,我们认为我们建立了一个良好的测试基础。未来的测试会进行更多的尝试,包括增强现有的测试,以及扩展测试场景。
我们认为把负载生成器限制在一个 Pod 中是一个最大的限制。这限制了负载的生成能力。如果突破了这一限制,我们就有能力进行更多样的测试方法。然而在多个 Pod 中并列运行,又带来了结果合并的问题。
后记
以下内容纯属个人胡言乱语
也不知道为啥,连续冒出几个性能测试来,与性能相比,更重要的是靠谱和有用好吗。Istio 还是 Linkerd,能长点心么。
参考资料
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。