Promethues 的 Agent 模式:高效转发云原生指标
原文:Introducing Prometheus Agent Mode, an Efficient and Cloud-Native Way for Metric Forwarding
Bartek Plotka 是红帽的首席软件工程师,从 2019 年开始担任 Prometheus 项目的维护者,也是 CNCF Thanos 项目的共同作者之一,同时还担任 CNCF 大使以及 CNCF 可观察性 TAG 的技术领导者。他在业余和 O’Reilly 出版了《Efficient Go》一书。
Promethues 对于目标的极度专注是我喜欢并加入这个项目的原因。Prometheus 用务实、可靠、经济的方式,推出了无价的指标监控系统。Prometheus 提供了极其稳定和健壮的 API、查询语言和用于进行集成的协议(例如远端写入和 OpenMetrics),这一稳固的基础,让云原生的监控生态欣欣向荣:
- 社区提供了包罗万象的 Exporter,例如容器、eBPF、我的世界甚至还有针对园艺的健康监测;
- 现在多数 CNCF 项目都会提供基于 HTTP/HTTPS 的
/metrics端点,让 Prometheus 可以读取指标数据。这原本是 Google 内部秘而不宣的一个概念,Prometheus 项目将其公诸于世; - 可观察性的范式发生了变化。从一开始 SRE 和开发者就非常依赖指标数据,对软件的韧性、排障能力以及数据驱动的决策过程产生了很好的推动作用
最后,我们极少会看到没有运行 Prometheus 的 Kubernetes。
备受瞩目的 Prometheus 社区让其它项目也同步成长,让 Prometheus 脱离了单节点部署的局限性(例如 Context、Thanos 等等),更有采用 Promethues API 和数据模型的云供应商(例如亚马逊和谷歌的托管 Promethues、Grafana 云等)。如果 Prometheus 只有一个原因,那么这个原因只能是——把监控社区的焦点聚集在重要的事情上面。
本文中将会介绍 Prometheus 的新特性:“Agent”。这一特性内置于 Prometheus 之中。Agent 模式禁用了 Prometheus 的一些特性,优化了指标抓取和远程写入的能力。这一特性使得一种新的应用模式成为可能。本文中我会陈述该功能让 CNCF 生态中游戏规则发生的变化——是的他让我非常兴奋。
转发模式的历史
Prometheus 的核心设计从未变更。这是一个向 Google Borgmon 监控系统 致敬的产品,要监控一个应用,就随应用部署一个 Prometheus 服务,告知 Promethues 如何联系到这个服务,允许 Prometheus 定期抓取当前的指标数据。这种工作方式通常被称为拉取模型,这种模型保障 Promethues 的轻量和韧性。另外它还极大简化了应用监控和 Exporter——只需要提供一个简单易读的 HTTP 端点,在其中提供 OpenMetrics 格式的当前指标值即可。这其中没有用到复杂的推送机制,也没有客户端库。一个简单的 Prometheus 监控部署如下图所示:
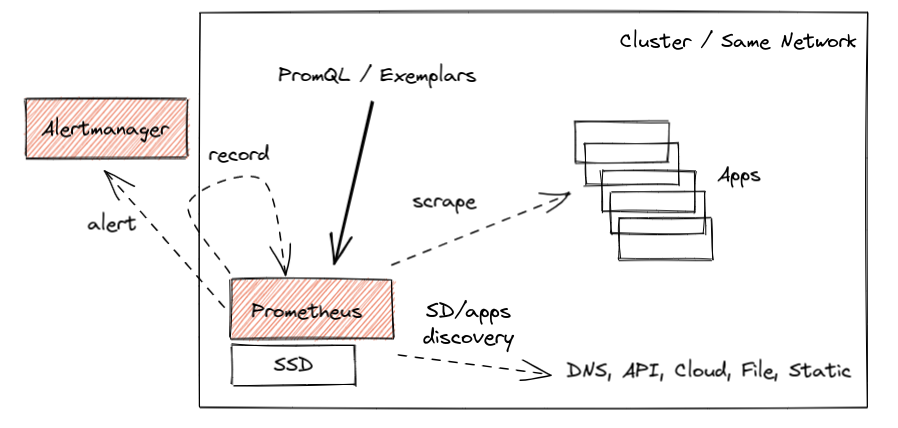
这种方式工作良好,过去几年中我们看到了上百万的部署案例,其中或长或短的留存了大量的监控数据。其中的指标数据可以进行查询、告警,并记录管理员和开发者都关注的数据指标。
然而云原生世界一直在发展和进化。随着托管 Kubernetes 方案的成长,几秒钟就能随需创建 Kubernetes 集群,我们已经能够把集群当做牲畜而非宠物(换句话说,我们不再关注特定的实例)。在 kcp 和 Fargate 中这样的产品中甚至没有了集群的概念。
另一个有意思的概念就是经常被用在电信、汽车和 IoT 领域的边缘集群和网络。我们会看到越来越多资源有限的小集群。规模限制导致他们无法在本地进行保存,包含监控数据在内的大量数据都需要被传送到远端的更大的节点上。
这意味着必须对必须对监控数据进行聚合,向用户进行呈现,甚至需要有全局级别的存储。这通常被称为全局视角。
要实现全局视角,最直接的办法就是在全局层次部署 Prometheus,通过远程网络抓去指标,或者从远端应用直接写入监控数据。我认为两种办法都烂透了,原因如下:
跨越网络边界的抓取行为会在监控管线中引入不确定因素。本地的拉取模型让 Prometheus 能够清晰获知待抓取目标的问题,例如宕机或者配置错误、重启、抓取缓慢(CPU 耗尽)、无法进行服务发现、缺乏访问凭据、DNS 故障,网络甚至整个集群失灵。外置抓取端引发的不稳定性可能让我们丢失信息。如果网络中断,可能会丧失可见性,相信我,不要这样做。
应用从远端直接向中心推送数据也不是什么好办法——尤其是在监控目标数量巨大时。得到指标之前,无法得到任何远端应用的信息,这个应用活着吗?是我的管线故障了吗?也许应用认证失败了?和前面的办法一样,跨网络的传输总面临着更大的风险。
Serverless 应用以及类似的短寿命容器经常会让我们将远端推送方式当做救命稻草。这种情况下我们希望把细碎的事件和指标能够聚合到一个较长存活期的时间序列里。我们对这一主题也进行了讨论,欢迎加入,一起完善这个方案。
Prometheus 用三种方式来支持全局视图,每种都有不同的优缺点。注意下图橘色部分:
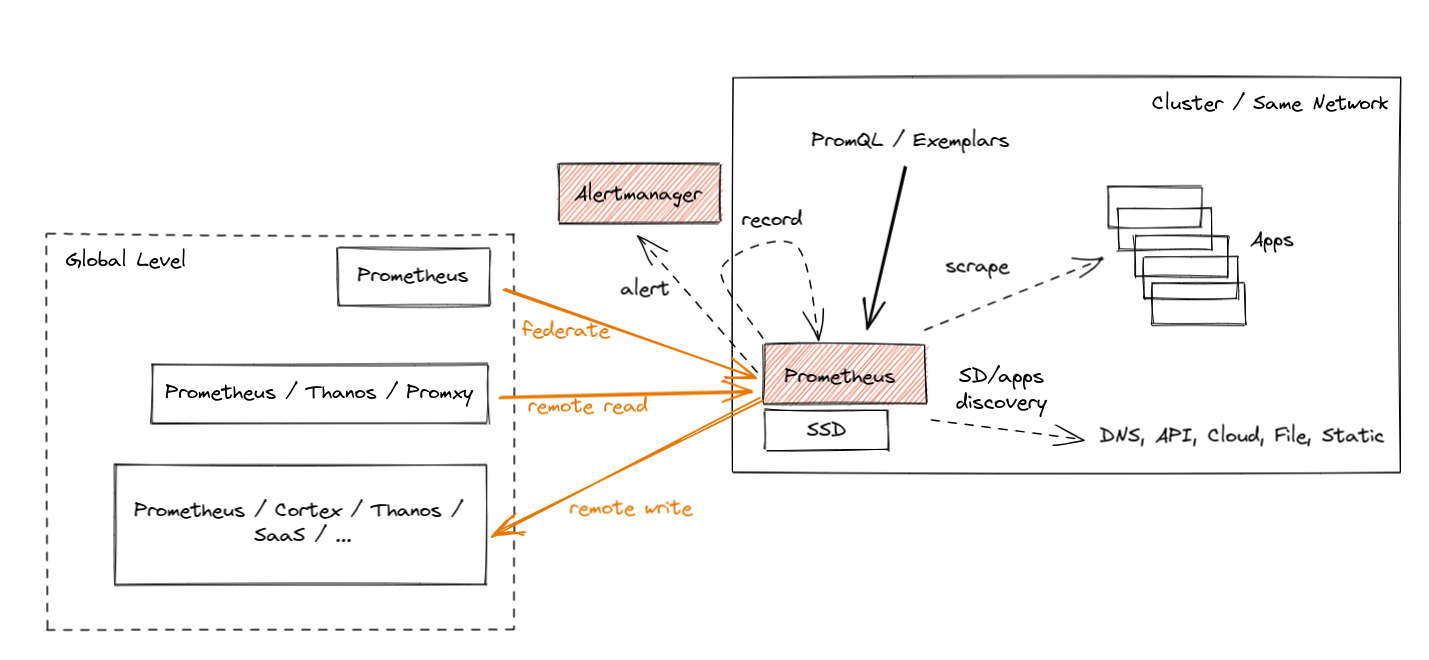
联邦:这是第一种用于聚合目的的方案。这种方案里,全局级的 Prometheus 服务器或从基层 Prometheus 中抓取指标的子集。这种级联方式里,联邦节点暴露的指标中包含了原始采样的时间戳,因此降低了跨网络抓取的风险,但是如果网络间的时延达到分钟级,可能就无法在不损失数据的情况下完成数据联合了。
Prometheus 远程读取:从远端 Prometheus 服务器的数据库中绕过 PromQL,直接提取原始数据。可以在全局一级部署 Prometheus 或者 Thanos 方案,用抓取自多个站点的远程数据来执行 PromQL 查询。这种方式很强大——数据存储在“本地”,还可以按需访问。不幸的是,这种方式也有缺点,如果没有 Query Pushdown,一个简单的查询可能就要拉取上 GB 的压缩数据。类似地,如果网络失联,服务就不可用了,另外有些集群只允许 Egress,禁止 Ingress
最后一种就是远程写入:这似乎是目前最流行的选择。Agent 模式也是聚焦于远程写入的,因此我们要详细描述一下这个模式
远程写入
Prometheus 远程写入协议让用户可以把部分或者全部指标数据写入到远端,可以对 Prometheus 进行配置,将一些指标(其中甚至可以代入所有的元数据和范例)转发给一个或多个远端的写入 API。实际上 Prometheus 是同时支持远端接收和写入的,所以可以部署全局级的 Prometheus 来接收跨集群的聚合数据。
Prometheus 远程写入 API 规范还在评审阶段,但整个生态接受了远端写入协议作为缺省指标导出协议。例如 Cortext、Thanos、OpenTelemetry 以及 Amazon、Google、Grafana、Logz.io 等云厂商,都支持这一协议的写入。
Prometheus 官方提供了官方的 API 兼容性测试,能通过远程写入合规性测试的方案,就可以提供远程写入的客户端能力。对于自行实现的工具来说这个功能非常有帮助,能帮助自实现工具确认协议实现的正确性。
抓取得到的流数据进行中心化存储之后,就有了全局视图的实现基础。这样也实现了关注点的分离。应用程序不受可观察性团队的管理的情况下,这种方式很有优势。这种方式让服务商们能够将这种工作从客户侧剥离开来,因此得以广泛采用。
但是 Bartek 你刚刚说过,从应用推送指标不是个好主意!
没错,不过有意思的是,远程写入的情况下,Prometheus 还是使用拉取模式从应用端获得指标数据的,然后对取样和序列进行批处理,把数据进行导出,推送到远程写入端点,有效地降低了中心点在应用失联时面临的风险。
远程写入的可靠性和效率,是一个亟待解决的难题。普罗米修斯社区花了大约三年的时间完成了稳定和可扩展的实现。WAL(写前日志)经过多次重构后,增加了内部队列、分片、智能备份等等。所有这些对用户来说都是隐藏的,用户可以在集中存储的场景下得到良好的流性能和数据量支持。
Katacoda 教程:远程写入
在 Prometheus 中这些都不新鲜,很多用户都在使用这种抓取应用信息后向远端进行写入的方式。
要体验这种远端写入能力,推荐使用 Katacoda 提供的 Prometheus 远程写入 Thanos 教程,其中解释了 Prometheus 远程转发的所有步骤。这个课程是免费的,注册账号尝试一下就好。
这里用接收模式的 Thanos 作为远程存储。现在还可以使用大量与远程写入 API 兼容的其它项目。
远程写入这么好,为什么还要给 Prometheus 加入 Agent 模式?
Prometheus 的 Agent 模式
Prometheus v2.32.0 开始,用户可以使用测试版参数 --enable-feature=agent 来启动启动 Prometheus。
Agent 模式优化了远程写入的用例。它禁止了查询、告警和本地存储,取而代之的是一个自定义的 TSDB WAL。其它部分原封不动:抓取逻辑、服务发现和相关的配置。如果只是想把数据转发到远端的 Prometheus 服务器或其它兼容的项目,这种方式非常值得一试。工作方式如下图所示:
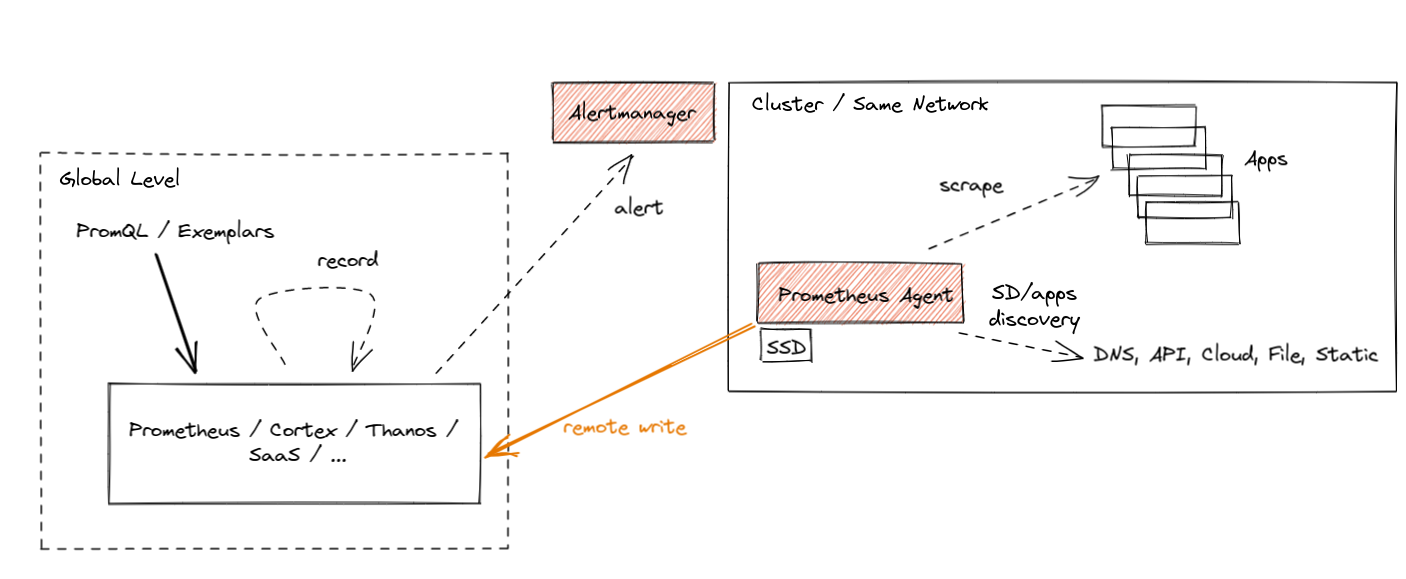
如果你不想在本地进行查询和告警,只是把指标输出到外部,使用 Agent 有什么好处呢?
第一个就是效率。Agent 中使用的 TSDB WAL 在转发成功后会立刻删除数据。如果远程端点无法连接,就会将数据保存起来,等待端点恢复。这种行为很像非 Agent 模式的 Prometheus,目前的缓冲有效期是两个小时,未来可能打破这个限制。这样一来我们就无需分配大块内存,也不用为查询准备完全索引。代理模式的资源消耗比标准服务实例低得多。
在边缘或者类似的环境中,CPU 和内存资源可能会很有限,效率是个非常重要的问题。另外目前使用指标进行监控的模式已经非常成熟。这意味着同样成本之下,能获得越多的监控指标,就越有性价比。
Agent 模式是针对特定使用场景的,标准模式的 Promethues Server 更稳定、更易维护,仍是缺省建议;Agent 模式的远端存储引入了更高的复杂性,还需谨慎使用。
另外,Agent 模式便于搭建纵向伸缩的数据接收架构。
指标接收端的弹性伸缩
数据抓取侧的自动伸缩方案需要根据抓取目标和指标数量进行判断。抓取的数据越多,就要自动部署更多实例。如果目标和指标数量下降了,就应该进行缩容,移除部分实例。自动伸缩能够降低 Promethues 规模调整造成的手工操作负担,并防止低谷期间浪费系统资源。
Server 模式的 Prometheus 是有状态的,很难应对这种需求。这种模式下搜集的数据保存在本地,缩容过程需要在中止实例之前将数据进行备份。接下来还要面对指标重叠、误导性的过期标记等问题。
这种场景下,我们需要能够聚合所有实例所有数据的全局视图(例如 Thanos Query 或者 Promxy)来进行查询。普通模式下的 Prometheus 的职责不仅限于指标采集,还包含了告警、录制、查询、压缩、远程写入等,这些任务都会消耗资源。
Agent 模式将服务发现、指标抓取和远程写入放到一个单独的服务中,如此就将工作焦点集中到了指标搜集上面。Agent 模式的 Prometheus 变得更加的“无状态”。是的为了防止数据丢失,我们需要部署一对 HA 实例,并挂接持久存储。但是技术上来说,我们有几千个目标(容器),我们可以部署多个 Prometheus Agent,安全地把抓取目标分配给特定实例。这么做的根本原因就是这些数据都会被推送给同一个中央存储。
总的说来,Agent 模式的 Prometheus 让自动的水平伸缩成为可能,从而有了针对监控指标规模变更进行应对的能力。我们将会和 Prometheus Kubernetes Operator 社区一起在这个方向努力。
那么 Agent 模式的 Prometheus 是否真的可用呢?
Agent 模式得到了大规模验证
Prometheus 会把 Agent 模式作为实验性功能加入下一个版本。参数、API 以及 WAL 的格式会发生变更。但是这种实现的性能已经在 Grafana Lab 的帮助下得到了实际验证。
Agent 的自定义 WAL 最初的实现是受到了 Robert Fratto 在 2019 年为 TSDB 实现的 WAL 的启发,期间得到了 Prometheus Maintainer Tom Wilkie 的指导。这个格式后来被用于 Grafana Agent 项目,得到了很多 Grafana 云的用户的采用。这一方案的成熟后,捐献给了 Promethues,希望得到集成和更多的发展和采用。Grafana 实验室的 Robert 在 Redhat 的 Srikrishna 以及社区帮助下,把这些代码移植到了 Prometheus,然后只用了半个月就合并进入到 main 分支。
有些 Prometheus Maintainer 也曾经为 Grafana Agent 项目贡献过代码,Grafana 的新 WAL 格式也是受到了 Prometheus WAL 格式的启发,捐献的过程非常平滑,并且目前的 Prometheus TSDB Maintainer 也能够方便的进行管理。并且 Robot 已经加入 Prometheus 团队,成为 TSDB 的 Maintainer。
接下来讲讲如何使用。
如何使用 Agent 模式
Prometheus 的帮助(--help 参数)内容中会看到类似内容:
usage: prometheus [<flags>]
The Prometheus monitoring server
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
(... other flags)
--storage.tsdb.path="data/"
Base path for metrics storage. Use with server mode only.
--storage.agent.path="data-agent/"
Base path for metrics storage. Use with agent mode only.
(... other flags)
--enable-feature= ... Comma separated feature names to enable. Valid options: agent, exemplar-storage, expand-external-labels, memory-snapshot-on-shutdown, promql-at-modifier, promql-negative-offset, remote-write-receiver,
extra-scrape-metrics, new-service-discovery-manager. See https://prometheus.io/docs/prometheus/latest/feature_flags/ for more details.
Agent 模式是需要用 --enable-feature=agent 参数的启用的。这种模式下能够使用同样的指标抓取配置以及远程写入能力。Agent 模式下,Web UI 的查询功能是被禁用的,只能用于展示构建信息、配置内容、抓取指标和服务发现信息。
在 Katacoda 上尝试 Prometheus Agent
可以在 Katacoda 上尝试 Promtheus Agent,真切体会其中的易用性。
崔秀龙
简单,是大师的责任;我们凡夫俗子,能做到清楚就很不容易了。